Links
Further information can be found in the course description and the current Moodle course.
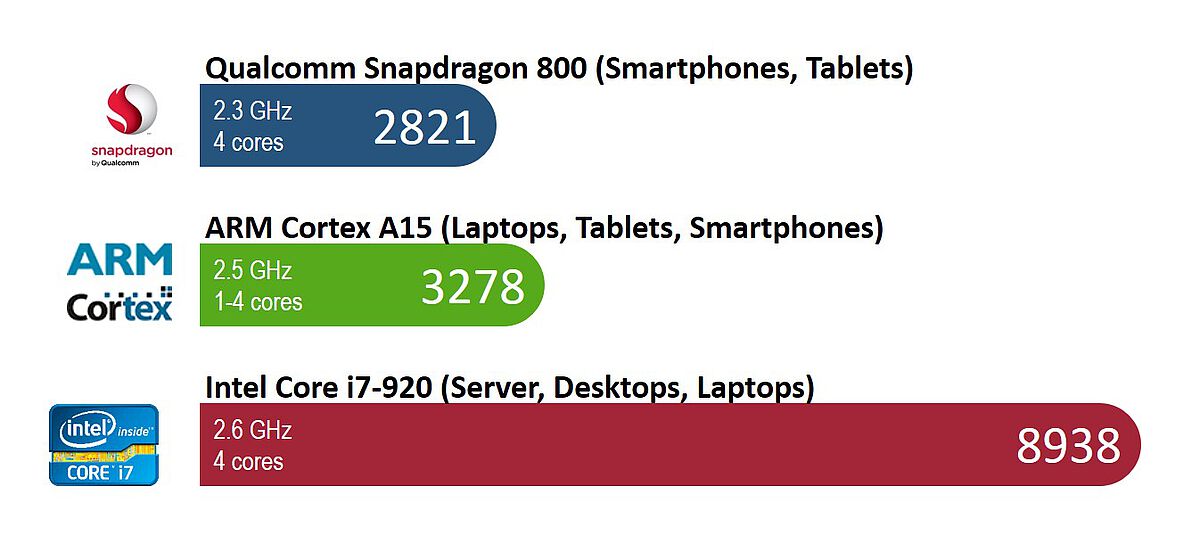
Smartphones, tablets, laptops etc.: modern processor technologies offer a plethora of devices with a wide range of capabilities. But if you look closely you will find that they all operate at around 2 GHz – so effectively your smartphone, tablet and desktop PC all have the same performance?
All modern processors come with an abundant number of cores. Since each core can perform a few billion operations per seconds, 32 cores means 32 times more operations, right? So is the Chinese Super-computer with 3.120.000 cores always faster than a desktop PC ?
In this lecture series you will get an understanding for processor architectures and their differences. You will learn the limitations of scalability & specialisation and their impact on programming & usage. The lecture will teach the basics of parallel and heterogeneous computing.
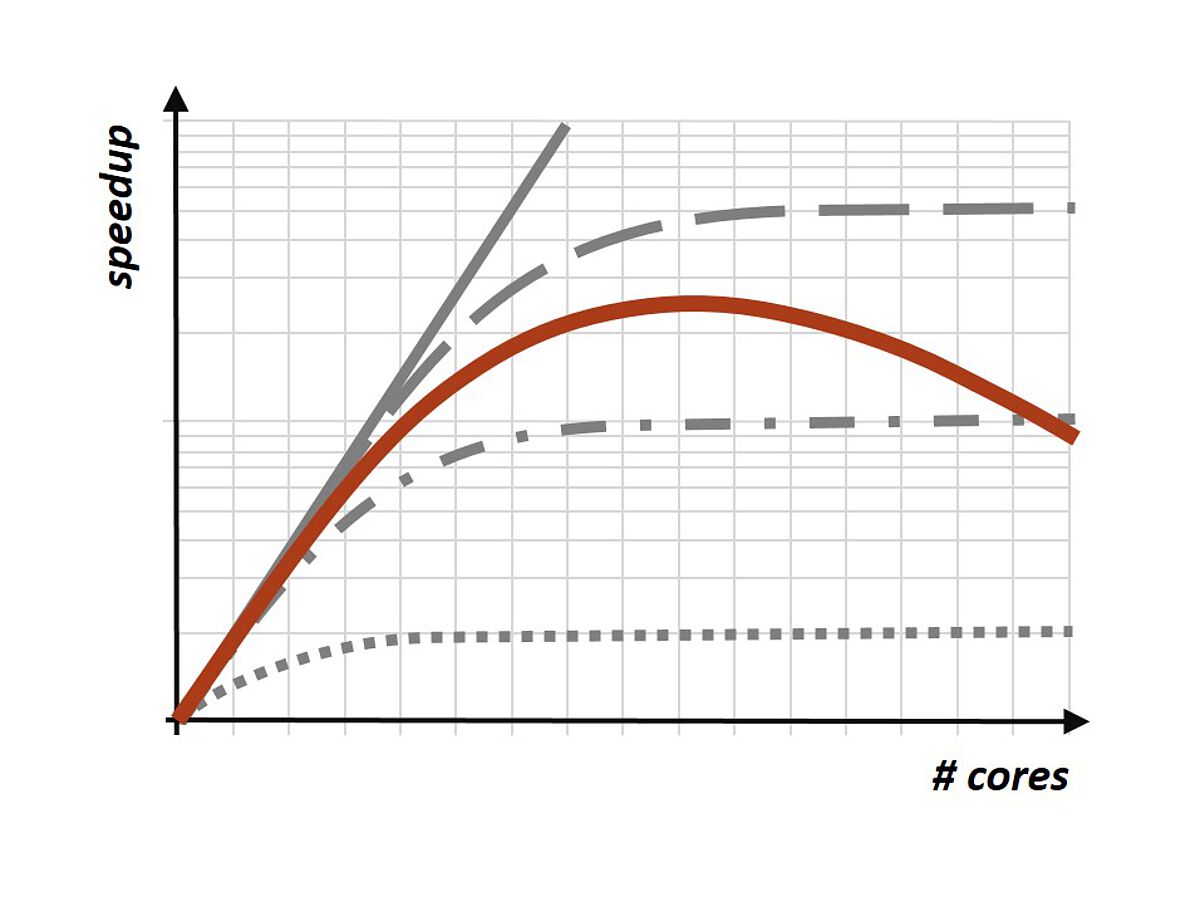
After this course students will have an in-depth understanding of processor architectures and their differences in modern heterogeneous computing platforms. They will understand the impact of processor and system architecture on application performance and will know how this affects programming of such systems. They will be able to explain the benefits and drawbacks of specialisation, parallelisation and data locality, and can give examples of how and when to exploit these factors. They will understand the limitations of scalability based on communication costs and lack of parallelism/amount of serial code and can interpret and explain scalability and speed-up diagrams for parallel applications. Participants will be able to argue where processor and system development is heading to, why and which problems will arise from this.
The course will start from an overview over current processor systems and development trends in computer hardware towards increased heterogeneity and specialisation, driven by the need for more computer performance and increased energy efficiency. The first section of the course will provide a base knowledge of processor architecture from a performance perspective. In a second section, the principles of parallelisation will be elaborated on all levels, from large scale computing systems, such as high performance computing and clouds, down to multi- and many-core processors. This covers the principles of parallel programming and programming models, such as OpenMP, MPI and Partitioned Global Address Space (PGAS). This will also cover their limitations, such as Amdahl’s law and the impact of data locality. The third section will address specialisation of systems, ranging from embedded devices and multi-core systems to specialised co-processors, such as GPUs. The impact of specialisation on performance and energy efficiency, but also on programmability and portability will be elaborated. The future trends towards completely heterogeneous setups on all levels will be examined and assessed. The lecture will conclude with an outlook on how processors will likely develop in the future and what this means for the programmability and portability of software.
Further information can be found in the course description and the current Moodle course.