Themen für Bachelorarbeiten, Masterarbeiten und Projekte
Unsere Themen für Bachelor- und Masterarbeiten sowie Projekte stammen aus den Bereichen Softwaretechnik und Programmiersprachen. Die konkreten Themen für Abschlussarbeiten orientieren sich an unseren Forschungsschwerpunkten und ermöglichen es den Studierenden, einen eigenen Beitrag zu einem Forschungsgebiet zu leisten. Zielgruppe sind vor allem die Studierenden der Studiengänge Informatik, Software Engineering, Medieninformatik, Künstliche Intelligenz und Cognitive Systems.
Diese Seite bietet eine Auswahl an Themen und Themenbereichen. Nähere Informationen erhalten Sie bei den jeweiligen Ansprechpartnern. Darüber hinaus sind wir offen für Ihre eigenen Themenvorschläge.
Ablauf einer Bachelor- bzw. Masterarbeit

Themenabstimmung und Proposal
Nach der initialen Kontaktaufnahme werden das Thema und die Inhalte der Bachelor- bzw. Masterarbeit abgestimmt und in einem Proposal festgehalten. Das Proposal hat sich als Tool zur Risikominimierung und Planung der Abschlussarbeit bewährt und beinhaltet:
- der Kontext der Abschlussarbeit
- die Forschungsfrage
- der Stand der Forschung
- die Lösungsidee
- die Methodik und der Evaluationsplan
Ein Großteil des Proposals kann eins zu eins in der Abschlussarbeit wiederverwendet werden.
Zwischenpräsentation
Im Rahmen der Zwischenpräsentation lernen Studierende Ergebnisse zu präsentieren und zu kommunizieren. Darüber hinaus kann im Rahmen der Zwischenpräsentation der bisherige Stand der Abschlussarbeit reflektiert und auf Feedback eingegangen werden.
Abgabe und finale Präsentation
Durch die Abgabe der Abschlussarbeit und die finale Abschlusspräsentation wird die Bachelor- bzw. Masterarbeit formal abgeschlossen.
(Legende - B: Bachelorarbeit, M: Masterarbeit, P: Projekt)
Human-centered Software Engineering
Dynamic and Static Program Analysis

Context
Most static analyzers rely on static dataflow analysis to detect problems like possible null pointer exceptions in code [5].
However, analyzers are usually unable to handle reflective or self-modifying code (e.g., Java Agents, Java Reflection, R's meta-functions [6]. While this is fine for languages in which such constructs are rare or discouraged, they are 1) used quite often in the R programming language and 2) pose an interesting problem to solve.
Problem
As a basis [3], I have previously created the static dataflow analyzer and program slicer flowR for the R programming language. However, it is currently unable to deal with these reflective and code-modifying constructs like eval, body, quote, and parse in its static dataflow graph.
While handling such constructs statically may be infeasible in the general case, we first want to focus on a set of common cases that appear frequently.
Tasks
- Develop a concept to represent code-modifications and lazy evaluation (within flowR's dataflow graph). For example, to represent a function that has the default values of its arguments or the contents of its body modified.
- Create a proof of concept implementation for this concept in flowR.
Related Work and Further Reading
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- A. Ko and B. Myers. Finding causes of program output with the Java Whyline.
- SonarQube, Sonar.
- Anckaert, B., Madou, M., De Bosschere, K. A Model for Self-Modifying Code.
If you want to, you can have a first look at flowR for yourself: https://github.com/Code-Inspect/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler
Context
Dataflow analysis is a very useful and important technique, used, for example, as part of compiler optimizations [1,2] and program comprehension techniques (e.g., slicing [3] or debugging [4]).
Although there is no single dataflow analysis (each analysis answers a slightly different question), dataflow analyzers usually identify how variables in a program relate to each other (e.g., which definitions a variable read my refer to).
Dataflow Analyzers can be split into:
- static analyzers if they use only the source code of a program as input, and
- dynamic analyzers if they use a specific program execution as input.
While static analysis is usually harder, it has lower application constraints as 1) it does not require inputs (from users, files, network-messages, ...), and 2) we do not have to deal with getting a potentially unknown program running. However, dynamic analyzers are usually much more valuable during debugging as they know the path the program took, the potential user inputs, the contents of external files, and more.
Problem
Within my master's thesis [3] that is now the basis of my PhD, I have created the static program slicer flowR for the R programming language, which includes a static dataflow analyzer. However, it offers no dynamic dataflow analysis and does not even attempt to run the respective input program.
Tasks
- Enrich flowR's existing pipeline of parsing, normalizing, static dataflow extraction, static slicing, and code reconstruction with a dynamic dataflow analysis step.
- Given a program (for starters without any external dependencies), the dynamic analysis should be able to determine the execution trace of the program (e.g., branches taken, loops entered and iteration requiered) with the help of R's debugging capabilities and active bindings [5].
- From that, it should be able to infer which variable references read which values (e.g., which definition of a variable was read), what functions have been called, ...
- The planned evaluation is to compare the results of the dynamic analysis with the results of the static analysis and to determine the differences.
Related Work and Further Reading
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- A. Ko and B. Myers. Finding causes of program output with the Java Whyline.
- R, Active Bindings
If you want to, you can have a first look at flowR for yourself: https://github.com/Code-Inspect/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler
Context
Static Program Analysis is a well-researched field [1,2], useful in various domains like compiler optimizations [3] and linting [4].
However, static analysis is unable to find semantic smells and bugs and requires a lot of work to set up.
On the other hand, current large language models (LLMs, like ChatGPT) can quickly answer questions about code and find (potential) semantic and syntactic bugs, with an easy-to-use interface and setup required.
Problem
Even though LLMs are easy to use and quick to give an answer, this answer is not always correct [5].
Furthermore, with their hype being relatively new, there is not much research on how their hallucinations hinder linting tasks or make them outright harmful.
To address that, we want to analyze common smells and errors in real-world code (including those that common linters can not find), synthetically generate code with these smells and errors, and then analyze how well LLMs can detect as well as "fix" them.
Tasks
- Identify common smells and errors in real-world R code.
- Synthetically generate code with these smells and errors.
- Analyze/Classify how well LLMs can detect and fix those problems.
Related Work and Further Reading
- García-Ferreira et al., Static analysis: a brief survey, 2016
- Anjana Gosain et al., Static Analysis: A Survey of Techniques and Tools, 2015
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- Hester et al., lintr: A 'Linter' for R Code, 2023
- Zhang et al., Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models, 2023
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler
Context
Dataflow analysis is a very useful and important technique, used, for example, to
- allow compiler optimizations [1,2],
- to aide program comprehension (e.g., [3] or debugging [4]), and
- perform code analysis (e.g., to locate possible null pointer exceptions [5]).
A static dataflow analyzer takes the source code of a program as its input and identifies how variables in a program relate to each other (e.g., which definitions a variable read my refer to).
However, this can happen on arbitrary granularity levels.
For example, when reading a single cell of an array, a coarsely grained analyzer may refer to any potential write to the array, while a more detailed analysis could restrict the definitions to those that modify the respective entry.
Problem
Within my master's thesis [3], which is now the basis of my PhD, I have created the static program slicer flowR for the R programming language, which includes a static dataflow analyzer.
However, it does currently not differentiate the individual cells of arrays or the attributes of an object (i.e., it does not analyze pointers) [6].
Tasks
- Extend flowR's static dataflow analysis with pointer analysis
- Differentiate Cells of a Vector with constant access
- Differentiate Data-Frames, Slots, and other pointer-types
- Track Aliases to identify when pointers relate to each other
- Evaluate the achieved reduction in the size of the resulting slices
Related Work and Further Reading
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- A. Ko and B. Myers. Finding causes of program output with the Java Whyline.
- SonarQube, Sonar.
- M. Hind. Pointer Analysis: Haven’t We Solved This Problem Yet?
If you want to, you can have a first look at flowR for yourself: https://github.com/Code-Inspect/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler
Relaxed Conformance Editing
Context
Graphical modeling is a widely used task in software and systems engineering. Similar to how an IDE assists with programming, graphical modeling tools are intended to help create models as efficiently as possible.
Basically, two types of graphical modeling tools can be distinguished: Either the tool is tailored to a graphical language and restricts the user in drawing in such a way that only syntactically correct models can be drawn (correct-by-constructionn approach), or one has a pure drawing tool that offers no language-specific support but allows maximum freedom. As so often, the optimum lies somewhere in between.
Problem
In this master thesis, a prototypical implementation of a graphical modeling tool in React is to be adapted in such a way that it is possible to turn various support mechanisms (and also restrictions) on or off.
A user study will then be conducted with this customizable tool, with the goal of finding the sweet spot between maximum restriction and maximum freedom. In order not to make the study too large, only a few useful combinations will be compared.
Task/Goal
- Familiarization with the corresponding tool
- Development and implementation of meaningful support or restriction options
- Conducting a user study (study design, creating user tasks, implementation, evaluation)
Needed skills
- Javascript/Typescript knowledge
- Experiences with React
- Interest in usability and study design
Further reading
Contact
Self-adaptive Systems
Self-Adaptive systems are systems that adjust themselves to maintain or improve their performance in response to changes in their environment and operational conditions, thereby ensuring continued effectiveness, reliability, and efficiency.
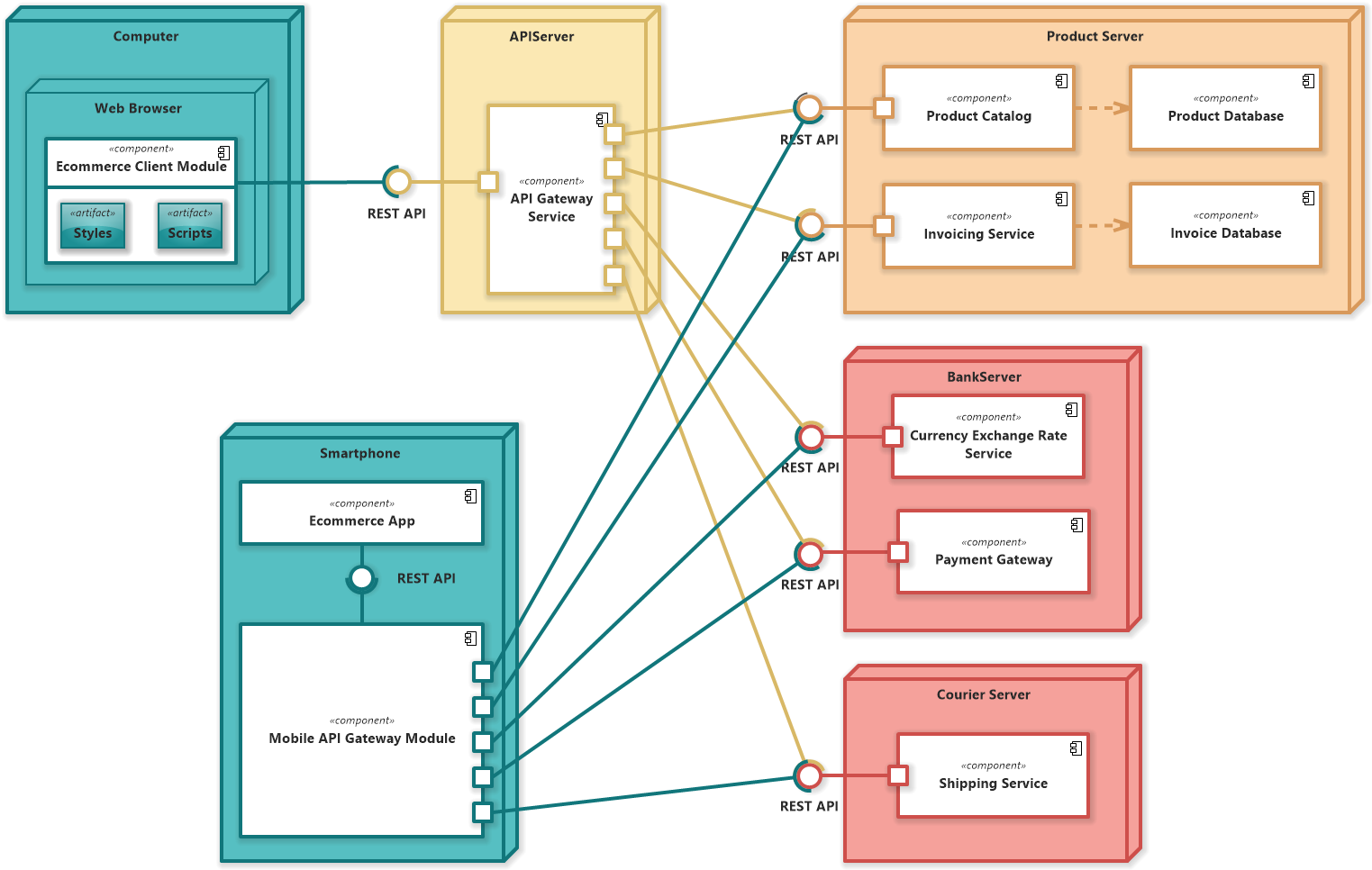
Self-adaptive systems are diverse and multifaceted, with applications extending across numerous fields. In our project, we concentrate on the cloud-native domain, with a special emphasis on the explainability aspect of self-adaptation. This involves delving into how these systems can not only adjust autonomously to changing conditions but also provide transparent and understandable explanations for their adaptations, ensuring clarity and trust in their operations.
Understanding the intricacies of self-adaptive systems, particularly in the cloud-native space, is a complex task. The autonomous adjustments these systems make in response to environmental changes can be intricate and opaque. This complexity underscores the necessity for effective visualization strategies.
Visualizations can range from simple schematic diagrams that illustrate system workflows, to advanced interactive visualizations that provide real-time insights into system dynamics. By employing visualization techniques like this, we aim to make the processes of self-adaptation in cloud-native systems not only more transparent but also more accessible to a broader audience, enhancing comprehension and facilitating informed oversight.
In this project you will integrate such an visualization approch. The implementation language is Typescript.
Context
Self-adaptive systems represent a significant leap in technology. These systems are capable of adjusting their behavior in response to changes in their environment or in their own state. This adaptability makes them incredibly powerful, yet also complex.
Large Language Models (LLMs) have shown remarkable proficiency in generating human-like text, offering potential as tools for simplifying and explaining complex technical concepts
We plan to use the capabilities of LLMs to explain these complex self-adaptive systems.
However, a significant challenge arises: how can these LLMs access detailed and up-to-date information about the self-adaptive systems they are explaining?
Problem
In this Master thesis, the different possibilities of enabeling the LLM to access the required data need to be explored. An example would be Retrieval Augmented Generation (RAG), which is already implemented in Libraries like LangChain.
A proptotype implementation has to be created and connected with the MENTOR project.
Finally, the appraoch has to be evaluted.
Tasks/Goals
- Familiarization with the possible approaches
- Implement a Prototype
- Evaluate the Implementation
Software Configuration
Feature Model Analysis
Context
A feature model of a configurable system can contain several anomalies, such as dead features, false-optional feature, or redundant constraints. There exist automated analyses for detecting these kinds of faults.
Problem
While many anomalies can be detected automatically, fixing them often requires a decision by a user on how to resolve the problem. The aim of this thesis is to investigate how and to what degree this process can be automatize.
Tasks
- Compare and discuss suitable strategies for cleaning (e.g., which redundant constraints to remove)
- Implement promising strategies in FeatureIDE
Contact
Context
Hidden features can be used to mark implementation artifacts that are not configurable by end users, but are automatically (de-)selected by the configuration editor according to the feature model. A hidden feature is called indeterminate if there is at least one configuration in which all regular features are defined but a value for the hidden feature cannot be deduced.
Problem
Indeterminate hidden features can cause a problem during configuration. Thus, these must be detected beforehand, which is a time-consuming task. The aim of the thesis is to optimize the current analysis for finding indeterminate hidden features such that it runs faster.
Tasks
- Improve the current analysis for finding indeterminate hidden features in FeatureIDE
- Evaluate the new method
Contact
Context
Given a list of configurations for a feature model (i.e., a sample), we often want to determine certain properties of it. For instance, for testing purposes, it is interesting how many potential feature interactions are covered by the sample. To this end, there exists a metric to measure t-wise interaction coverage. However, in literature the definition of this metric is often ambiguous or only given implicitly.
Problem
Due to the ambiguous definition of the coverage metric, there are multiple different variants. For example, one could include or exclude core and dead features for counting feature interaction. The same is true for abstract features. Other design decisions for the metric are whether to merge atomic sets an whether to count invalid interactions. In general, it is unclear by how much the choice of a specific metric variant impacts the results and what metric is best used in which case. This makes measuring coverage difficult and hampers comparability of new metrics and sampling tools in literature and in practice.
Tasks
- Research which variants of the metric are used in literature
- Evaluate the impact of using different variants on the same sample
Contact
Formal Languages for Variability
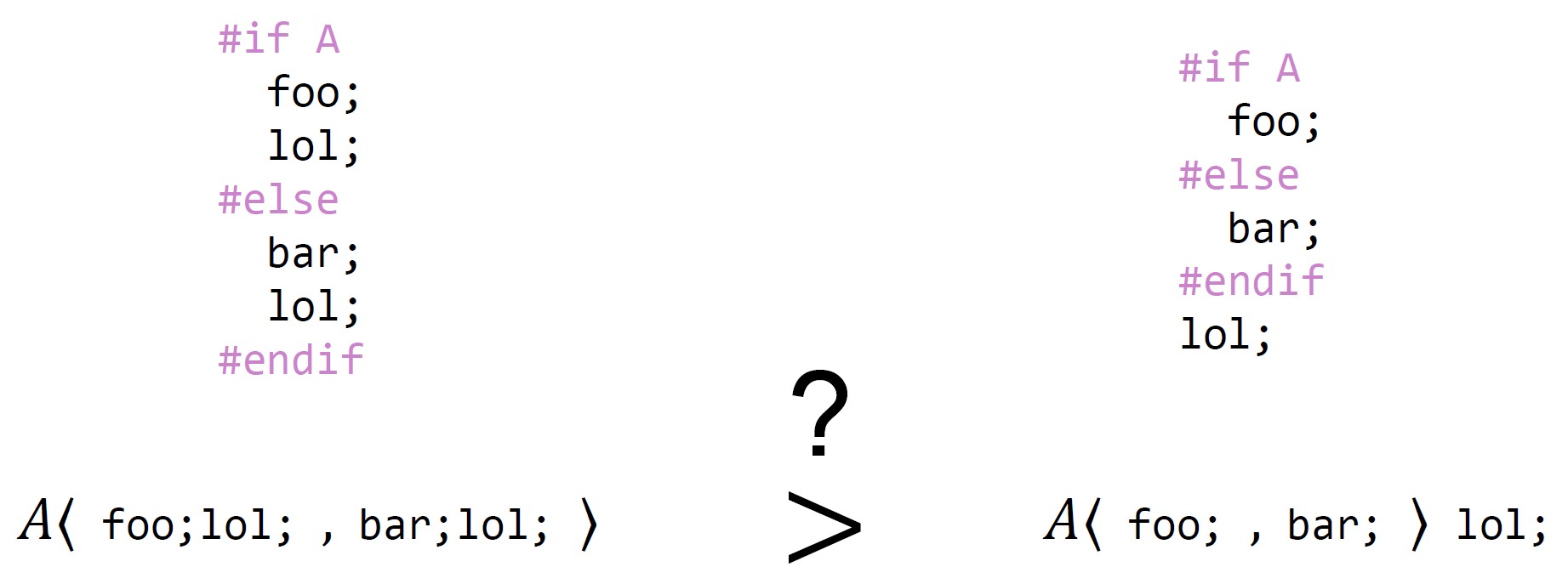
Problem
When it comes to developing multi-variant software systems, software product-line engineering and analyses avoid duplicate computational effort by exploiting similarities between the different software variants. For example, in the above example the statement "lol;" is shared between the software variants including or excluding feature A. To describe and analyze variability, formal languages have been proposed that allow semantic-preserving translations to refactor expressions to increase sharing. However, the notion of having "more sharing" in a formula remains vague most of the time or different metrics have been used in the literature to measure sharing.
Task
- Literature survey on sharing metrics (for formal variability languages)
- Qualitative comparison between sharing metrics
- Definition of new metrics if necessary
- Perhaps empirical evaluation of different metrics for real systems
Related Work
Contact
Constraint-Programmierung und Constraint Handling Rules
Constraint Handling Rules
We are developing a rule-based implementation of a tool to analyse and generate graphs. It is used in the domain of mason’s marks. For thousands of years, stonemasons have been inscribing these symbolic signs on dressed stone. Geometrically, mason’s marks are line drawings. They consist of a pattern of straight lines, sometimes circles and arcs. We represent mason’s marks by connected planar graphs. Our prototype tool for analysis and generation of graphs is written in the rule-based declarative language Constraint Handling Rules. One or several of following features could be improved in this proposed work:
Goals/Tasks
- improve the vertex-centric logical graph representation, i.e. adding arcs, colors, labels,
- encode existing mason marks either by hand, from images or import from existing databases,
- recognize (sub)graphs and patterns in a graph, in particular (self-)similarities and correlations between graphs,
- perform classical algorithms on graphs like shortest paths,
- derive properties and statistics from graphs,
- generate (randomly or exhaustively) and draw graphs from given constrained subgraphs based on properties and statistics.
References
Prerequesites
- Good knowledge of Prolog and CHR
- Lecture Rule-based Programming
Contact
When algorithms are written in CHR, constraints represent both data and operations. CHR is already incremental by nature, i.e. constraints can be added at runtime. Logical retraction adds decrementality. Hence any algorithm written in CHR with justifications will become fully dynamic. Operations can be undone and data can be removed at any point in the computation without compromising the correctness of the result.
A straightforward source-to-source transformation can introduce justifications for user-defined constraints into the CHR. Then a scheme of two rules suffices to allow for logical retraction (deletion, removal) of constraints during computation. Without the need to recompute from scratch, these rules remove not only the constraint but also undo all consequences of the rule applications that involved the constraint.
Goal
Further work should investigate implementation, dynamic algorithms and application domains of CHR with justifications:
- research how logical as well as classical algorithms implemented in CHR behave when they become dynamic.
- improve the implementation, optimize and benchmark it.
- support detection and repair of inconsistencies (for error diagnosis), - support nonmonotonic logical behaviors (e.g. default logic, abduction, defeasible reasoning).
References
- Thom Frühwirth: Justifications in Constraint Handling Rules for Logical Retraction in Dynamic Algorithms.
- CHR translator
Prerequisites
- Good knowledge of Prolog and CHR
- Lecture Rule-based Programming
- Interest to learn about formal analysis methods of rule-based languages
Contact
Extend the analysis techniques and/or the associated tool from the following two research papers:
A dynamic program analysis of the non-termination problem for recursion in the Constraint Handling Rules (CHR) language: A simple program transformation for recursive rules in CHR was introduced that produces one or more adversary rules. When the rules are executed together, a non-terminating computation may arise. It was shown that any non-terminating computation of the original rule contains this witness computation.
References
- Thom Fruehwirth: A Devil's Advocate against Termination of Direct Recursion, PPDP 2015.
- Transformation Tool available (use "Devil" options).
A static program analysis of the non-termination problem for recursion in the Constraint Handling Rules (CHR) language: Theorems with so-called misbehavior conditions for potential non-termination and failure (as well as definite termination) of linear direct recursive simplification rules are given. Logical relationships between the constraints in a recursive rule play a crucial role in this kind of program analysis.
References
Prerequesites
- Lecture "Rule-Based Programming"
Contact

In distributed computation, data and processes are distributed over a network of stores and processing units. In a constraint-based programming language paradigm this means that constraints have to be annotated with spatial information defining their whereabouts. Obvious topologies are a distinction between global and local stores as well as trees. Localized constraints can also be used for so-called reified (or meta-)constraints (e.g. https://sicstus.sics.se/sicstus/docs/4.0.8/html/sicstus/Reified-Constraints.html), to store justifications and for spatial reasoning.
In Constraint Handling Rules (CHR), there is a simple source-to-source program transformation that adds local annotations to constraints.
The scope of the work includes implementation of such a transformation, their application and/or static program analysis to derive distribution patterns, i.e. to localize constraint computation while minimizing communication overhead.
References
- Edmund S. L. Lam, Iliano Cervesato and Nabeeha Fatima: CoMingle: Distributed Logic Programming for Decentralized Mobile Ensembles. In proceedings of International Conference on Distributed Computing Techniques (Coordination'15)
- A. Raffaeta and T. Frühwirth: Spatio-Temporal Annotated Constraint Logic Programming, Third International Symposium on Practical Aspects of Declarative Languages (PADL'01), Las Vegas, USA, March 2001.
- T. Frühwirth: Entailment Simplification and Constraint Constructors for User-Defined Constraints, Third Workshop on Constraint Logic Programming (WCLP 93), Marseille, France, March 1993.
Prerequesites
- Lecture "Rule-Based Programming"
Contact
Invariants (or assertions, properties, conditions) annotate program text and express static and dynamic properties of a program's execution. Invariants can be expressed as logical relations (predicates) over the program's variables. In the context of constraint-programming and Constraint Handling Rules (CHR), they amount to constraints. These can be readily added to the program to enforce the invariants. By comparing the program with and without invariants expressed as constraints using established program analysis techniques for CHR, namely confluence and program equivalence, we can check if the invariants hold in the program.
Furthermore, invariants can be strenghened and even be generated by adapting the so-called completion method (that is normally used to generate additional rules to make a CHR program confluent).
References
Prerequisites
Contact
Program slicing is a program anaylsis technique whereby one extracts properties and relationships of variables in a program by removing from the program all statements that do not effect the assignments of the variables. In the context of constraint programming and Constraint Handling Rules that deal with logical relations (predicates) this amounts to the logical operation of variable projection. This means that we remove unwanted variables that are not of interest from the program by program transformation. This transformation can be accomplished by adapting the technique of "completion". It is usually used to make a non-confluent program confluent.
References
Prerequisites
- Lecture "Rule-based Programming
Contact

Repeated recursion unfolding is a new approach that repeatedly unfolds a recursion with itself and simplifies it while keeping all unfolded rules. Each unfolding doubles the number of recursive steps covered. This reduces the number of recursive rule applications to its logarithm at the expense of introducing a logarithmic number of unfolded rules to the program. Efficiency crucially depends on the amount of simplification inside the unfolded rules. A super-linear speedup is provably possible in the best case, i.e. speedup by more than a constant factor. The optimization can lower the time complexity class of a program.
Goals
The goal is to implement this optimization scheme as a program transformation in the programming language of choice. If necessary, the scheme should be transferred from recursion to iteration constructs such as loops.
References
Prerequisite
- Excellent knowledge and programming skills in the choosen programming language.
Contact
Prolog (WAM) and then Java (JVM) popularized the concept of an abstract (or virtual) machine to implement programming languages in a systematic, portable yet efficient way. Such a machine shall be developed for CHR.
Goals
Define the abstract code instructions for CHR and to implement them.
Prerequesites
- Good knowledge of Prolog and CHR
- Lecture Rule-based Programming
- Lecture Compiler Construction (Compilerbau) (optional but very helpful)
Contact
FreeCHR
The declarative programming language Constraint Handling Rules (CHR) is designed as a language extension to other, not necessarily declarative programming languages. There are existing implementations for Prolog, C, Java, JavaScript, and others. We want to conduct a Structured Literature Research (SLR) on existing implementations, to get an exhaustive overview over implementation techniques and patterns.
Goals
- Conduct an SLR on papers on existing CHR implementations
- Find CHR implementations without a scientific publication on public repositories on, e.g. GitHub, GitLab, ...
- Identify and document common architectures, implementation techniques and patterns
- Get an exhaustive overview over existing and historic CHR implementations
References
- T. Frühwirth: Constraint Handling Rules - What Else?
- S. Sneyers et al.: As time goes by: Constraint Handling Rules
- P. Van Weert: Efficient Lazy Evaluation of Rule-Based Programs
- P. Van Weert, P. Wuille, T. Schrijvers, B. Demoen: CHR for Imperative Host Languages
- F. Nogatz, T. Frühwirth, D. Seipel: CHR.js: A CHR Implementation in JavaScript
- Dragan Ivanović: Implementing Constraint Handling Rules as a Domain-Specific Language Embedded in Java
Prerequesites
- Interest in programming languages and (to some extend) compiler construction.
- Good knowledge of multiple programming languages and paradigms.
Contact
FreeCHR aims to be a sound and complete embedding framework for CHR. Hence, we want to extend the operational semantics by possibly failing computation, as they are necessary for the development of constraint solvers and other software.
Goals
- Extend the very abstract operational semantics of FreeCHR, such that they can model possibly failing computations
- Prove soundness and completeness w.r.t. the very abstract operational semantics of CHR
- Optional: Develop an execution algorithm and prove correctness w.r.t. the new operational semantics
References
- S. Rechenberger, T. Frühwirth: FreeCHR - An Algebraic Framework for CHR Embeddings
- T. Frühwirth: Constraint Handling Rules (ISBN: 978-0-521-87776-3)
Prerequesites
- Interest in formal aspects of programming languages
- Interest/knowledge in category theory and/or type systems is recommended
- Knowledge in functional programming, especially monads
Contact
FreeCHR aims to be a sound and complete embedding framework for CHR. Hence, we want to extend the operational semantics by stateful computation, as they are common in many programming languages.
Goals
- Extend the very abstract operational semantics of FreeCHR, such that they can model stateful computations
- Prove soundness and completeness w.r.t. the very abstract operational semantics of CHR
- Optional: Develop an execution algorithm and prove correctness w.r.t. the new operational semantics
References
- S. Rechenberger, T. Frühwirth: FreeCHR - An Algebraic Framework for CHR Embeddings
- T. Frühwirth: Constraint Handling Rules (ISBN: 978-0-521-87776-3)
Prerequesites
- Interest in formal aspects of programming languages
- Interest/knowledge in category theory and/or type systems is recommended
- Knowledge in functional programming, especially monads
Contact
FreeCHR aims to be a sound and complete embedding framework for CHR. The abstract operational semantics are a next step in the direction of modelling the necessities of real-life programming languages. Hence, we want to re-formalize them in the context of FreeCHR and establish soundness and completeness.
Goals
- Formalize the abstract operational semantics ωt of CHR in the terms of (side-effect free) FreeCHR
- Prove soundness and completeness of the new definition
References
- S. Rechenberger, T. Frühwirth: FreeCHR - An Algebraic Framework for CHR Embeddings
- T. Frühwirth: Constraint Handling Rules (ISBN: 978-0-521-87776-3)
Prerequesites
- Interest in formal aspects of programming languages
- Interest/knowledge in category theory and/or type systems is recommended
Contact