Themen für Bachelorarbeiten, Masterarbeiten und Projekte
Unsere Themen für Bachelor- und Masterarbeiten sowie Projekte stammen aus den Bereichen Softwaretechnik und Programmiersprachen. Die konkreten Themen für Abschlussarbeiten orientieren sich an unseren Forschungsschwerpunkten und ermöglichen es den Studierenden, einen eigenen Beitrag zu einem Forschungsgebiet zu leisten. Zielgruppe sind vor allem die Studierenden der Studiengänge Informatik, Software Engineering, Medieninformatik, Künstliche Intelligenz und Cognitive Systems.
Diese Seite bietet eine Auswahl an Themen und Themenbereichen. Nähere Informationen erhalten Sie bei den jeweiligen Ansprechpartnern. Darüber hinaus sind wir offen für Ihre eigenen Themenvorschläge.
Ablauf einer Bachelor- bzw. Masterarbeit

Themenabstimmung und Proposal
Nach der initialen Kontaktaufnahme werden das Thema und die Inhalte der Bachelor- bzw. Masterarbeit abgestimmt und in einem Proposal festgehalten. Das Proposal hat sich als Tool zur Risikominimierung und Planung der Abschlussarbeit bewährt und beinhaltet:
- der Kontext der Abschlussarbeit
- die Forschungsfrage
- der Stand der Forschung
- die Lösungsidee
- die Methodik und der Evaluationsplan
Ein Großteil des Proposals kann eins zu eins in der Abschlussarbeit wiederverwendet werden.
Zwischenpräsentation
Im Rahmen der Zwischenpräsentation lernen Studierende Ergebnisse zu präsentieren und zu kommunizieren. Darüber hinaus kann im Rahmen der Zwischenpräsentation der bisherige Stand der Abschlussarbeit reflektiert und auf Feedback eingegangen werden.
Abgabe und finale Präsentation
Durch die Abgabe der Abschlussarbeit und die finale Abschlusspräsentation wird die Bachelor- bzw. Masterarbeit formal abgeschlossen.
Foliensatz Abschlussvorstellung 03.02.2026: Link
(Legende - B: Bachelorarbeit, M: Masterarbeit, P: Projekt)
Human-centered Software Engineering
Algorithm Detection
Context
We are convinced that automatically detecting algorithm implementations in a code base can be helpful to gain knowledge about, which concerns are present in the code base, how they are solved and which components are involved. This knowledge can then support the tasks of software comprehension, software architecture recovery and software maintenance.
Examples of algorithms that could be interesting to detect and some of the insights their detection provides:
- Quicksort -> The application sorts data structure x.
- A* -> The application does path search.
- Raft (Consensus Algorithm) -> The application is a distributed, fault-tolerant system.
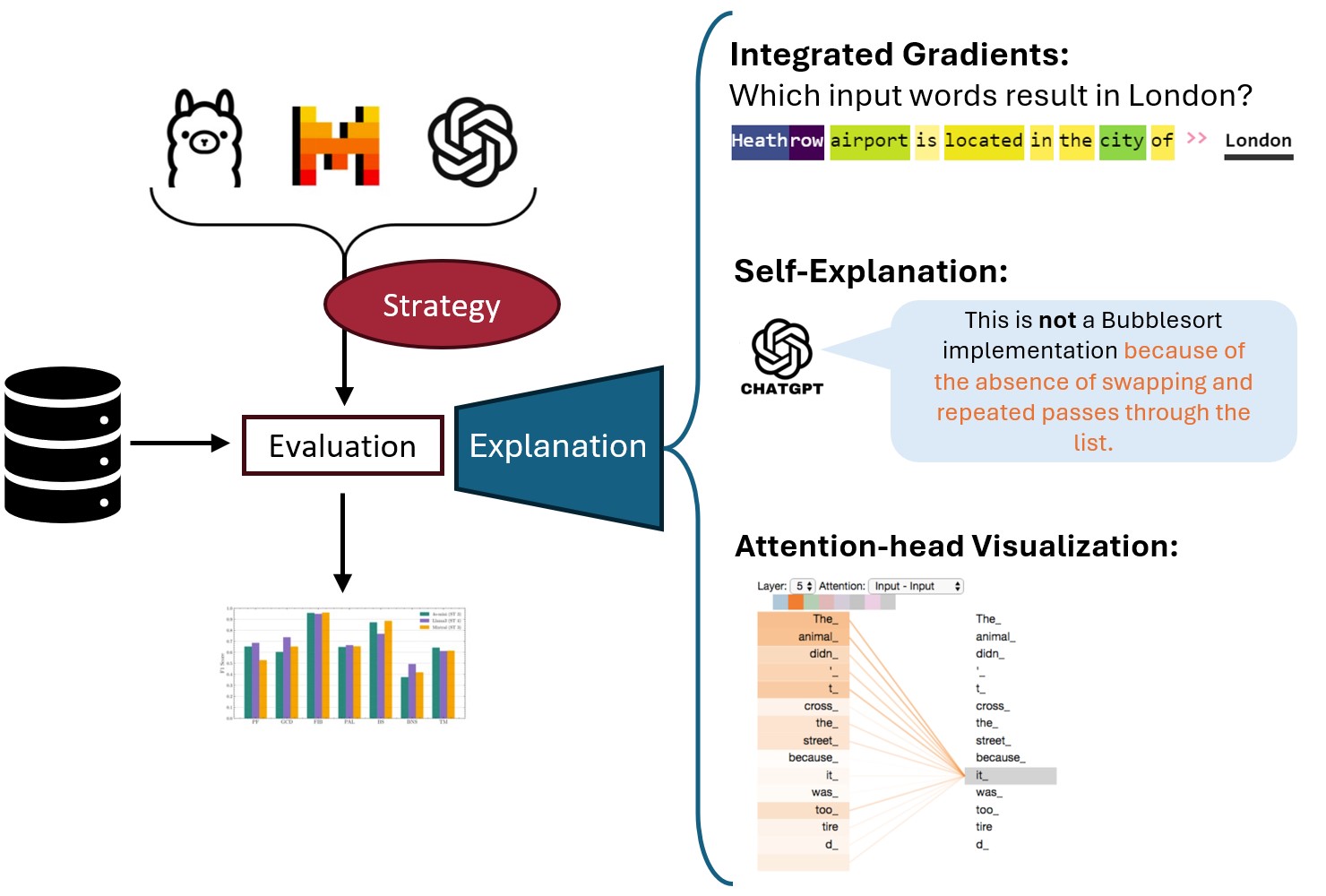
Research Question
Large Language Models (LLMs) achieve impressive results on code-related tasks such as code clone detection, code summarization and code generation.
Our first experiments using LLMs for algorithm detection indicate promising performance, with F1 scores of about 77%.
However, our evaluation has so far not focused on the analysis of failure cases.
We are interested in evaluating why and in which cases LLMs fail.
Therefore, the main research question of this thesis is:
- What are the reasons for LLM failures when used for algorithm detection?
Tasks
- Asses the suitability of different explanation techniques (Self-Explanations, Attention Visualization, Shaply Values, LIME).
- Select and evaluate two explanation techniques (Self-Explanations, Attention Visualization) for different failure cases and possibly different LLMs.
No prior knowledge of machine learning (ML) is required for this thesis. However, you should be open to familiarizing yourself with a new subject area.
Related Work
- Publications regarding explanations:
- Interesting Repositories:
Contact
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Dynamic and Static Program Analysis

Context
Classical code coverage techniques are widely used to give an indication of the quality of a test suite (with respect to its capability in detecting faults within the system under test).
However, they are not always effective and can be outright misleading [1, 2]. Consider a scenario in which you simply execute code within a unit test but never check whether the resulting state is as expected.
While (at least for most languages) this still ensures that the code does not raise a runtime exception, this is way too weak for most use-cases.
As one possible solution, Schuler and Zeller introduced the concept of checked coverage [3], which uses dynamic slicing to only consider the executed code that contributed to something which is checked with an assertion. Later work by Zhang and Mesbah [4] showed that such checked coverage is indeed a strong indicator of the effectiveness of a test suite.
Research Problem
In this work, we want to look at an alternative to dynamic slicing - static slicing, which does not execute the code and hence over-approximates all potential executions. In contrast to a dynamic slice on an assertion, the static slice contains all the code that could potentially affect the assertion, even if it is not executed in a particular test run. This way, we obtain additional information about the test suite and the system under test, yet we do not know whether this information is useful to gauge the effectiveness of the test suite.
Tasks
More specifically the intended steps of this work are as follows:
- Consider a well-supported language such as Java alongside an appropriate 1) static slicer, 2) dynamic slicer, and 3) coverage tool.
- Use these tools to compute the static and dynamic slices for test-suites of real-world Java projects.
- Analyze, compare, and discuss the results of the static and dynamic slices with respect to the code coverage and the effectiveness of the test suite (e.g., using mutation testing).
Related Work and Further Reading
- H. Hemmati, "How Effective Are Code Coverage Criteria?," 2015 IEEE International Conference on Software Quality, Reliability and Security, Vancouver, BC, Canada, 2015, pp. 151-156.
- Laura Inozemtseva and Reid Holmes. 2014. Coverage is not strongly correlated with test suite effectiveness. In Proceedings of the 36th International Conference on Software Engineering (ICSE 2014). Association for Computing Machinery, New York, NY, USA, 435–445.
- Schuler, D. and Zeller, A. (2013), Checked coverage: an indicator for oracle quality. Softw. Test. Verif. Reliab., 23: 531-551.
- Yucheng Zhang and Ali Mesbah. 2015. Assertions are strongly correlated with test suite effectiveness. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015). Association for Computing Machinery, New York, NY, USA, 214–224.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
Context
Let us assume you are a happy researcher! You just found a great paper that describes an interesting analysis accompanied with several figures illustrating the result. If the results are to be believed, you might want to apply the same analysis to your own data. However, when you try to reproduce the figures (and are lucky enough that the script runs through), you notice that they look different than in the paper. Even though the changes might be minimal in many cases (e.g., different labels, colors, or scales), they can also be more severe with different shapes, missing data points, or even completely different results.
Problem
Given a paper and the accompanying reproducibility package, we want to automatically match the figures in the paper with those best matching those generated by the package, identifying any differences. As a possible extension, we want to identify the section of the code responsible for the figure and guess the reason for the differences (or at least provide the information to the researcher to check).
Potential Tasks
- Research existing approaches for figure comparison and code provenance analysis (e.g., [1,2])
- Implement a prototype for the figure comparison (e.g., using image processing techniques or vector graphics analysis)
- Evaluate the prototype and analyze the results and identify potential reasons for differences (e.g., by tracing back to the code sections responsible for figure generation)
- Link the findings back to the code (e.g., by identifying figure creations in the source code and using program slicing to extract the relevant parts [3])
Related Work and Further Reading
- M. Nuijten and J. Polanin. “statcheck”: Automatically detect statistical reporting inconsistencies to increase reproducibility of meta-analyses
- Standardization of Post-Publication Code Verification by Journals is Possible with the Support of the Community [more specifically CODECHECK]
- F. Sihler and M. Tichy. Statically Analyzing the Dataflow of R Programs.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[de] P: Paket-Übergreifende Statische Programm-Analyse (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/bilder/flowR/flowr-project-graphics.png)
[2–6 Students] [AP SE] [PSE1] [PSE2]
Statische Analyse bezeichnet die Untersuchung von Programmen auf Laufzeiteigenschaften ohne diese tatsächlich auszuführen. Sie ist ein integraler Bestandteil moderner Softwareentwicklung und hilft beim Identifizieren von Fehlern, Sicherheitslücken oder dem Verbessern der Lesbarkeit. Compiler verwenden statische Analyse beispielsweise, um Typfehler zu vermeiden oder möglichst optimalen Code zu generieren. Entwicklungsumgebungen oder Language Server verwenden statische Analyse, um Ihre Funktionalität wie Refactorings oder Autovervollständigung zu realisieren (Siehe dazu auch Foliensätze statische Programmanalyse).
In diesem Projekt geht es um die Arbeit an und um flowR, einem Framework für die statische Analyse von R, einer statistischen Programmiersprache die häufig in der Datenanalyse und -visualisierung eingesetzt wird. Eine ausgiebige Analyse des Daten- und Kontrollflusses ermöglicht es flowR beispielsweise ein Programm nur auf die Teile zu reduzieren, die für die Generierung einer Grafik oder die Berechnung eines statistischen Modells relevant sind (das sogenannte Program Slicing) oder mittels Abstract Interpretation die Wertebereiche von Variablen zu bestimmen.
Über flowR
Aktuell kann flowR als Erweiterung für Visual Studio Code, Positron und RStudio, sowie direkt als Docker Image verwendet und ausprobiert werden. Folgende Zeile ermöglicht euch beispielsweise, flowR mit seinem read-evaluate-print loop zu erkunden:
docker run -it --rm eagleoutice/flowr:latest
Wenn ihr dann im REPL zum Beispiel den Datenflussgraph eines R Ausdrucks sehen wollt, könnt ihr folgendes eingeben:
R> :df! x <- 2
Zum Verlassen, genügt ein :q flowR wird unter der GPLv3 Lizenz auf GitHub hauptsächlich in der Programmiersprache TypeScript entwickelt. Die ausführliche Dokumentation erfolgt über ein dediziertes und automatisch aktualisiertes Wiki und direkt im Code.
(Mögliche) Ziele
Dieses Semester ist das Anwendungsprojekt für flowR denkbar flexibel gestaltet und bietet eine Vielzahl an spannenden möglichen Bereichen (die sich so oder so ähnlich auch in Richtung einer Abschlussarbeit ausbauen lassen). Folgende Liste stellt einige mögliche Aufgabenbereichen vor, mit denen Ihr euch in flowR verwirklichen könnt. Die konkrete Zuteilung erfolgt dann zu Beginn des Projekts, je nach Interesse:
- Sicherheitsanalysen — Rs tief verwurzelte, dynamische Natur erlaubt zwar zum einen eine hohe Flexibilität und eine explorative Analyse von Daten, birgt aber auch gleichzeitig zahlreiche Risiken, vor allem wenn R-Code aus unsicheren Quellen ausgeführt wird. Daher möchten wir flowR um klassische Sicherheitsanalysen erweitern um Sicherheitslücken wie Code Injection oder Improper Input Validation zu erkennen.
- Transitive Paket-Analysen — flowR bietet mittlerweile eine fundierte Grundlage um den Daten- wie auch Kontrollfluss von R Skripten aber auch ganzen Paketen zu analysieren (und das ziemlich schnell, so benötigen wir mit 16 Kernen nur etwas mehr als eine Stunde um alle aktuellen Paketversionen zu analysieren). Allerdings verbleiben diese Ergebnisse gerade noch auf der Ebene einzelner Pakete und ignorieren die zusätzlichen Möglichkeiten von Paket-Übergreifenden Analysen, wie beispielsweise das nachverfolgen von Datenflüssen über Paketgrenzen hinweg.
- Dynamisches Laden von Code — Machen wir es kurz, R ist eine wundervolle Sprache. Kein Wunder, dass eine solche Sprache daher auch Möglichkeiten bietet, Code und auch bereits im Voraus berechnete Datensets durch diverse Binärformate dynamisch zu laden. Gerade solche Funktionen stellen allerdings eine große Herausforderung für statische Analysen dar, da der Code und seine Auswirkungen, bzw. die Daten so erst zur tatsächlichen Laufzeit bekannt sind. Gerade für die Fälle, in denen die geladenen Daten oder der Code bereits zur Analysezeit (wenn auch nur teilweise) vorliegen, möchten wir flowR dahingehend erweitern, dass solche dynamisch geladenen Inhalte auch in die Analyse einbezogen werden können.
- Erkennen impliziter Annahmen für externe Daten — Das durchschnittliche Analyse-Skript sieht wie folgt aus: Geladene Daten werden zunächst bereinigt, transformiert und anschließend analysiert oder visualisiert. Dabei werden allerdings häufig implizite Annahmen über die Struktur und den Inhalt der Daten getroffen (z.B. dass eine Spalte nur numerische Werte enthält oder dass keine fehlenden Werte vorliegen). Solche Annahmen können zu Fehlern führen, wenn die tatsächlichen Daten nicht den Erwartungen entsprechen oder sich später ändern. Fehler, welche sich häufig nicht oder nur sehr spät auch bei der Ausführung bemerkbar machen, da sie zwar die diese impliziten Annahmen verletzen, aber dennoch plausibel wirkende Werte produzieren. Mithilfe von flowR wollen wir nun Techniken entwickeln, um solche impliziten Annahmen statisch zu inferieren und in die Analyse einzubetten.
- Erklärbare Datenflussanalyse und API — Statische Programmanalyse ist ein wundervolles Themenfeld mit vielen komplexen Algorithmen und Techniken, die in einem emergenten Zusammenspiel die Analyse auch komplexer Programmsemantiken erlauben. Allerdings führt diese Komplexität auch dazu, dass die Details für Nutzer:innen von statischen Analysen häufig schwer nachvollziehbar sind und selbst vermeintlich einfache APIs eine Reihe an Annahmen Treffen, welche die "einfache" Nutzung erschweren. Hier geht es also darum, die bestehenden Analysen und APIs von flowR so zu erweitern und instrumentieren, dass diese die konkreten Schritte einer Analyse nachvollziehbar machen.
- Quellcode-Transformation — Statische Analyse wird häufig dafür genutzt um Fehler in Programmen zu finden oder Informationen über deren Verhalten zu gewinnen. Allerdings können wir viele Fehler bereits automatisch beheben (wie z.B. mit Quick-Fixes bei Lintern), Programme optimieren oder automatisiert instrumentieren um dann bei Ihrer Ausführung weitere Informationen zu erhalten. Dafür benötigen wir allerdings eine Möglichkeit, den R-Code auf syntaktischer Ebene transformieren und dann wieder zurück in Quellcode übersetzen zu können. Damit soll flowR um ein solches Quellcode-Transformations-Framework (vgl. Spoon) erweitert werden.
Interesse? Dann melde dich doch gerne bei mir und werde Teil des flowR Teams!
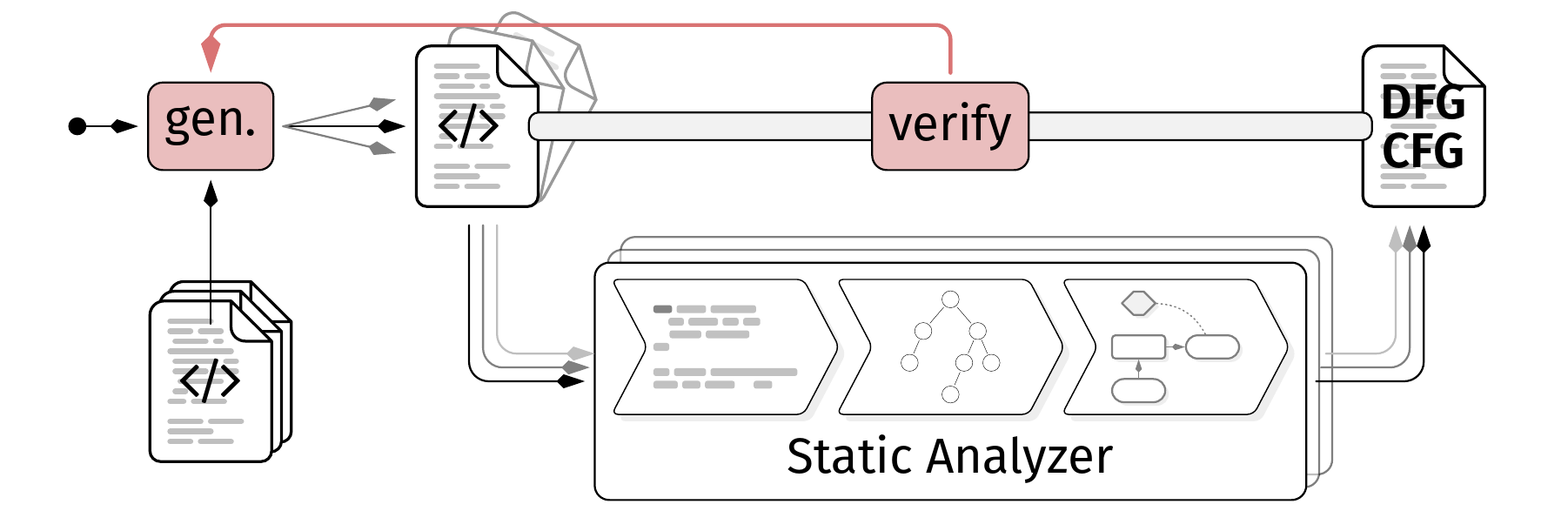
Context
Static program analysis is a wonderful topic and a gigantic area with countless application domains such as optimization, verification, and bug detection. While building such tools is already a challenging task, ensuring that they actually work correctly and provide high-quality results is even more difficult. Modern programming languages ship with complex and ever-evolving features, making it hard to cover all of them correctly. This is made even harder with underspecified and constantly changing language semantics, or languages in which the semantics leave behaviors undefined and up to the implementation (e.g., C/C++). While proofs and formal verification can help to ensure correctness, they usually verify the correctness of the theoretical concept behind the analysis with the theoretical model of the programming language in an idealized environment, not the actual implementation of the analysis tool with all its engineering decisions, optimizations, and quirks on real-world platforms. To compensate this we want to develop techniques to automatically check the correctness and quality of static analysis tools.
Problem
Given a static analyzer such as flowR [1], generate strategies to produce program to analyze (either taken from mutations of real-world sources or synthetically generated [2]) and use them to evaluate the correctness and quality of the analysis results. These strategies can require executable programs to compare the dynamic behavior with the static prediction, or just static code snippets to check for soundness and precision of the analysis (cf. [3]).
Potential Tasks
- Research existing approaches for automatic correctness and quality analysis of static analysis tools (e.g., using metamorphic testing [2])
- Implement a prototype framework to generate input programs for a given static analysis tool (e.g., flowR) and use them to evaluate the correctness and quality of the analysis results, using various strategies.
- Evaluate the effectiveness of the generated test cases in finding issues in the static analysis tool.
Related Work and Further Reading
- F. Sihler and M. Tichy. Statically Analyzing the Dataflow of R Programs.
- Chen T., Kuo F., Liu H. et al. Metamorphic Testing: A Review of Challenges and Opportunities
- An issue summarizing current ideas
If you want to, you can have a first look at flowR for yourself!
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[RESERVED] B/M: Dead/Unused Code Detection for R (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/dead-code-graphic.png)
Context
Dead or unused code describes all parts of a program that are either never executed at runtime or never used in any way.
Such parts hinder not only the readability of the program — requiring users first to realize that such snippets do not actually contribute to the program's functionality — but also the maintainability of the code, as users may be afraid that the code could be used in some way [1, 2].
Additionally, dead code can lead to performance issues, as it may cause the definitions of many unused functions, the loading of unnecessary datasets, or the calculation of values that are never used.
Research Problem
Given an R program and information on its control- and dataflow, identify the dead and unused code within the program adapting well known algorithms to the dynamic nature of the R programming language [3,4,5]. For this, we use a static dataflow analyzer called flowR [6] which provides us with a control flow and a dataflow graph.
Tasks
More specifically, the task are:
- Adapt the dead code elimination problem to the R programming language and discuss which code can be removed safely
- Use flowR's control flow and dataflow graph to identify the dead code using your adapted algorithm
- Evaluate and discuss the effectiveness of your algorithm on a set of real-world R programs
Related Work and Further Reading
- S. Romano, C. Vendome, G. Scanniello and D. Poshyvanyk, "A Multi-Study Investigation into Dead Code," in IEEE Transactions on Software Engineering, vol. 46, no. 1, pp. 71-99, 1 Jan. 2020.
- Simone Romano, Giovanni Toriello, Pietro Cassieri, Rita Francese, and Giuseppe Scanniello. 2024. A Folklore Confirmation on the Removal of Dead Code. In Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering (EASE '24). Association for Computing Machinery, New York, NY, USA, 333–338.
- Jens Knoop, Oliver Rüthing, and Bernhard Steffen. 1994. Partial dead code elimination. In Proceedings of the ACM SIGPLAN 1994 conference on Programming language design and implementation (PLDI '94). Association for Computing Machinery, New York, NY, USA, 147–158.
- Rastislav Bodík and Rajiv Gupta. 1997. Partial dead code elimination using slicing transformations. In Proceedings of the ACM SIGPLAN 1997 conference on Programming language design and implementation (PLDI '97). Association for Computing Machinery, New York, NY, USA, 159–170.
- I. Malavolta et al., "JavaScript Dead Code Identification, Elimination, and Empirical Assessment," in IEEE Transactions on Software Engineering, vol. 49, no. 7, pp. 3692-3714, July 2023.
- github.com/flowr-analysis/flowr
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[RESERVED] B/M: Automatically Infer Code-Constraints (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/bilder/flowR/code-contracts.png)
Context
Let's suppose you are a data scientist tasked with the analysis of a dataset. As an expert of the domain you have a quick look at the dataset and remember an older script by a colleague which already loads, prepares, and transforms the dataset as you want! Reusing it just leaves you with the task of visualizing the data (as is the common workflow) so you quickly write up and run the script... and luckily realize that even though the script runs and produces figures eerily close to what you would expect, something is not right. The dataset of your colleague never contained a zero so the script contains the implicit assumption of being just able to divide cells.
Within this work we want to make such implicit assumptions explicit in the code, alerting users whenever they no longer hold!
Problem
You have an R script together with the statically inferred dataflow graph that informs you about the control and data dependencies of function calls, variables, and definitions in the program.
The challenges are to
- identify points of interest at which the behavior of the program is defined,
- infer contracts that represent the potential implicit assumptions at the given position (e.g., that the value of a variable has to be non-zero, smaller than the length of another vector, ...), and
- instrument the code to automatically verify these constraints from now on.
Of course, the specific scope of these challenges as well as the focus depends on whether you want to do this as a bachelor's or master's thesis as well as your personal preference.
Tasks
- Enrich flowR [4], a dataflow analysis framework for the R programming language, with the capability to infer predefined constraints
- Create an initial collection of sensible constraints to infer (e.g., non-zero values, ...)
- Infer these constraints and instrument the program to reflect them [5]
One way to infer such constraints would be the definition of abstract domains [1] although classical optimization techniques such as constant folding and constant propagation help as well [2, 3].
Related Work and Further Reading
- P. Cousot. Principles of Abstract Interpretation. (ISBN: 978-0-26-204490-5)
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- B. Meyer, Applying "Design by Contract"
If you want to, you can have a first look at flowR for yourself: https://github.com/flowr-analysis/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
Self-adaptive Systems
Context
Self-Adaptive systems are systems that adjust themselves to maintain or improve their performance in response to changes in their environment and operational conditions, thereby ensuring continued effectiveness, reliability, and efficiency.
Self-adaptive systems are diverse and multifaceted, with applications extending across numerous fields. In our project, we concentrate on the cloud-native domain, with a special emphasis on the explainability aspect of self-adaptation. This involves delving into how these systems can not only adjust autonomously to changing conditions but also provide transparent and understandable explanations for their adaptations, ensuring clarity and trust in their operations.
In the MENTOR project, we use Palladio Component Models (PCM) of Self-Adaptive Microservices to simulate the system. These simulations are used to analyze and improve the performance of the systems reconfiguration behavior. To test the performance of our appraoch, we need PCM models of different systems to ensure generalizability and detect potential issues with our approach.
Problem
In this Master thesis, a prototype implementation of a PCM model generator has to be created. This prototype should get a set of constraints (e.g., Nmin≤∣C∣≤Nmax; ∀s∈S:λmin≤ArrivalRate(s)≤λmax; ∀(ci,cj)∈PotentialConnections:Lmin≤Latency(ci,cj)≤Lmax; ∀c∈Cpattern∖{ccenter},c→ccenter) and generate one or multiple pcm models satisfying the constraints. The generated models then have to be verified to ensure that they are well formed.
To generate the models, we imagine a combination of a constraint solver and a LLM. However, we are also open to other appraoches, for example using Answer Set Programming.
Tasks/Goals
- Familiarization with the PCM meta model
- Familiarization with constraint solver, LLMs, etc.
- Implement a Prototype
- Evaluate the Implementation
- Implement a Prototype
- Evaluate the Implementation
Context
Self-Adaptive systems are systems that adjust themselves to maintain or improve their performance in response to changes in their environment and operational conditions, thereby ensuring continued effectiveness, reliability, and efficiency.
Self-adaptive systems are diverse and multifaceted, with applications extending across numerous fields. In our project, we concentrate on the cloud-native domain, with a special emphasis on the explainability aspect of self-adaptation. This involves delving into how these systems can not only adjust autonomously to changing conditions but also provide transparent and understandable explanations for their adaptations, ensuring clarity and trust in their operations.
In the MENTOR project, we use Palladio Component Models (PCM) of Self-Adaptive Microservices to simulate the system. These simulations are used to analyze and improve the performance of the systems reconfiguration behavior. To test the performance of our appraoch, we need PCM models of different systems to ensure generalizability and detect potential issues with our approach.
Problem
Our state graphs get too large to display. We need to visualize all states in a comprehensive and understandable way. Ensure the visualization is intuitive and easy to understand
Tasks/Goals
- Develop visualization concepts for Large State Graphs
- Implement the delevoped visualization concepts
- Develop the solution in React/Typescript
Idea:
- Use Reinforcement Learning to optimize reconfiguration of cloud systems
- Simulation based on Palladio Component Models (PCM) using Slingshot
- Integrate Slingshot into Gymnasium environment
Tasks:
- Literature Research: different RL algorithms (Pros, Cons, Setup)
- Design a vectorized state based on simulation results (Critical)
- Perform extensive experiments and evaluate different algorithms and hyperparameters
GenAI for Control and Embedded SE
Context
LLMs are increasingly being used to assist with programming or as a standalone tool for generating programs. However, the domains in which these techniques are applied are often (web-based) applications or mobile apps.
However, a large part of software development takes place in the domain of embedded systems. Software is used to control small machines (such as washing machines) as well as large systems.
Problem
LLMs have not yet made much inroads into this area of software development, and there are many reasons for this: proprietary, sometimes graphical programming languages, fear of internal company knowledge leaking out, very high security and performance requirements, necessary specific knowledge about the structure of a system, etc.
Goal
The objective of this work is to systematically identify the specific problems associated with the introduction of coding LLMs in the creation of control and automation software and, based on this, to derive proposals for how this situation can be improved.
To this end, an interview study will be conducted with approximately 20 companies, the results of which will be evaluated qualitatively and, if necessary, quantitatively, and finally systematically processed.
Specifically, we would like to find answers to the following questions:
Why are current LLMs not or only rarely used in the field of control and automation software development?
What experiences have developers in this domain had with LLMs so far?
What are the requirements that companies place on an AI tool so that they can use it productively in their environment?
Needed skills
- Good communication skills
- Nice to have: experience in conducting interview study
Contact
Configurable Software Systems
Identification of Feature Interactions in Configurable Software
Context
In software product lines, variability is determined by features that can be included or excluded to create a specific configuration. T-wise sampling algorithms aim to generate samples that cover every possible combination of t features in at least one configuration within the sample set.
Problem
Some products/configurations may contain bugs resulting from errors that arise when multiple features are combined. These faulty feature interactions can potentially mask other errors. Currently, error masking/shadowing in configurable software is understudied that is why we want to investigate this topic.
Tasks
- Research on occurencies of complex feature interaction bugs and error masking bugs in configurable software systems
- Detect, compare, and discuss the complex feature interactions
Contact
Quality-driven System Evolution
Architecture-based Modelling and Analysis of Security
Motivation
Moderne Softwaresysteme sind zunehmend komplex und vernetzt, was eine umfassende Analyse zur Sicherstellung von Qualitätsmerkmalen wie Vertraulichkeit unerlässlich macht. Eine architekturbasierte Vertraulichkeitsanalyse ermöglicht die frühzeitige Erkennung potenzieller Verstöße gegen die Vertraulichkeit und trägt somit zur effektiven Vermeidung von Datenlecks bei. Allerdings erschweren Unsicherheiten im System selbst sowie in seiner Umgebung eine präzise und vollständige Analyse der Softwarearchitektur. Die hohe Komplexität architektonischer Modelle und die Vielzahl möglicher Unsicherheiten führen darüber hinaus zu einer kombinatorischen Explosion, die eine automatisierte Modellreparatur erheblich erschwert. In der Praxis müssen Softwarearchitekt:innen daher alle Verstöße manuell beheben – ein aufwändiger und fehleranfälliger Prozess. Zwar existieren bereits Ansätze zur Identifikation von Vertraulichkeitsverletzungen unter Unsicherheit, jedoch fehlt es bislang an wirksamen Methoden zur Minderung ihrer Auswirkungen.
Aufgabenstellung
Im Rahmen dieser Arbeit entwickeln Sie einen innovativen Ansatz zur automatisierten Behebung von Vertraulichkeitsverletzungen in Datenflussdiagrammen unter Nutzung von Sprachmodellen wie GPT. Dazu wird das Modell in einem strukturierten Format (z.B. JSON) an das
Sprachmodell übergeben. Das Sprachmodell soll daraufhin einen Lösungsvorschlag generieren. Die Qualität der vorgeschlagenen Lösung wird anschließend mithilfe eines von uns bereitgestellten Analyseverfahrens überprüft. Basierend auf dieser Bewertung wird ein iterativer Feedback-Loop mit dem Sprachmodell aufgebaut, um die Ergebnisse sukzessive zu verbessern.
Kontakt
Bei Interesse und/oder Fragen können Sie mich jederzeit kontaktieren. Wir können das Thema gerne weiter besprechen und versuchen, es an Ihre persönlichen Wünsche anzupassen.
Robert Heinrich (Institute Homepage)
Motivation
Moderne Softwaresysteme sind zunehmend komplex und vernetzt, was eine umfassende Analyse zur Sicherstellung von Qualitätsmerkmalen wie Vertraulichkeit unerlässlich macht. Eine architekturbasierte Vertraulichkeitsanalyse ermöglicht die frühzeitige Erkennung potenzieller Verstöße gegen die Vertraulichkeit und trägt somit zur effektiven Vermeidung von Datenlecks bei. Allerdings erschweren Unsicherheiten im System selbst sowie in seiner Umgebung eine präzise und vollständige Analyse der Softwarearchitektur. Die hohe Komplexität architektonischer Modelle und die Vielzahl möglicher Unsicherheiten führen darüber hinaus zu einer kombinatorischen Explosion, die eine automatisierte Modellreparatur erheblich erschwert. In der Praxis müssen Softwarearchitekt:innen daher alle Verstöße manuell beheben – ein aufwändiger und fehleranfälliger Prozess. Zwar existieren bereits Ansätze zur Identifikation von Vertraulichkeitsverletzungen unter Unsicherheit, jedoch fehlt es bislang an wirksamen Methoden zur Minderung ihrer Auswirkungen.
Aufgabenstellung
Ziel dieser Arbeit ist die Entwicklung eines Verfahrens zur automatisierten Behebung von Vertraulichkeitsverletzungen in Softwarearchitekturen mithilfe diskreter Optimierungstechniken. Dabei sollen gezielte Modelländerungen vorgenommen werden, um alle identifizierten Verstöße zu beseitigen – und gleichzeitig die Änderungskosten so gering wie möglich zu halten. Hierfür ist zunächst eine geeignete Kostenfunktion für Modelländerungen zu definieren. Anschließend soll ein Optimierungsansatz (z.B. basierend auf Integer Linear Programming oder Constraint Solving) entwickelt und implementiert werden, der eine optimale Reparaturlösung ermittelt. Die Qualität der Lösung wird mithilfe einer bestehenden Analyse validiert und kann mit anderen Reparaturansätzen verglichen werden.
Kontakt
Bei Interesse und/oder Fragen können Sie mich jederzeit kontaktieren. Wir können das Thema gerne weiter besprechen und versuchen, es an Ihre persönlichen Wünsche anzupassen.
Motivation
Choosing inappropriate configurations of blockchain systems for decentralized applications (DApps) can entail serious issues, including exposure to attacks, too slow performance, and high costs. Such inappropriate blockchain system configurations can even require migrating to a new system, which is extremely difficult once a blockchain system is deployed. Every node would need to set up a completely new blockchain system, and crucial data could get lost. To configure blockchain systems that meet DApp requirements on dependability, decentralization, and performance, software architects need tooling to simulate and analyze the influence of blockchain system configurations on the behaviors and quality of blockchain systems before deployment. In particular, novel modeling, simulation, and prediction approaches are needed to estimate and explain the behavior of blockchain systems to ensure they meet DApp requirements on dependability before setup.
Topic Overview
Within the context of developing suitable blockchain systems for DApps, several topics for Bachelor/Master thesis are available as listed in the following. In addition to these topics, we will be happy to discuss your own ideas for thesis topics on blockchain technology.
- DApp Archetypes: Develop archetypal DApps that can be used to bootstrap productive DApps.
- Mitigation of Security Risks by Design: Develop new security analyses for blockchain systems to help improve their robustness against common attacks (e.g., selfish mining attacks) by design.
- Modeling and Simulation: Design a modeling language to represent blockchain systems or DApps using the Palladio modelling and analysis approach. Implement an extension for the Palladio analysis tool to assess blockchain systems for security vulnerabilities or performance bottlenecks. Evaluate your extension of the Palladio tool.
- Trade-offs in Blockchain Systems: Develop new analysis techniques to assess the quality attributes and behaviors of blockchain systems with a focus on the blockchain trilemma.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time. We can discuss the topic further and try to adapt it to your personal preferences.
Context
Attack analysis is typically conducted by cybersecurity experts, who possess in-depth knowledge in this field. However, cybersecurity experts often do their job in the development phase, or even after the software system is released. When designing the software architectures or cyber-physical systems (CPSs), architects often miss the security aspects due to their knowledge.
Problem
The attacks can propagate through the system due to a misconfiguration or an unawareness of the implicit access control policies. Selecting an appropriate mitigation technique requires a lot of expert knowledge.
Tasks/Goals
- Research and develop an approach to use architectural analysis and a large language model (LLM) to mitigate an attack.
- Using architecture, we use Palladio Component Model (PCM) as the architectural description language, and ask LLM to identify the vulnerabilities and provide a suggestion to mitigate the vulnerabilities.
- Analyse the attack propagation with the proposed mitigation.
Contact and More
If you are interested and/or have any questions, feel free to contact us any time. We can discuss the topic further and try to adapt it to your personal preferences.
Context
We developed an Eclipse-based attack propagation analysis tool. This tool helps architects to analyse how an attack propagates through their architecture at design time by modelling vulnerabilities and conducting the attack analysis.
Problem
Our tool is developed based on Eclipse Modeling Tools, therefore it needs to be installed on the architect's machine. Sometimes, they need to install third-party libraries before using our tool. In addition, our tool also needs graphical features to make the modelling task easier.
Tasks
- Develop an online modelling tool to allow modelling an attacker by using a website.
- Develop the function for the online tool to allow conducting an attack propagation analysis.
- Develop the extract function of the online tool to deliver an attractive attack graph.
Results
- A website that allows users to conduct an attack propagation analysis.
- The online tool can be shipped as a dockerized package.
Contact and More
If you are interested and/or have any questions, feel free to contact us any time. We can discuss the topic further and try to adapt it to your personal preferences.
Motivation und Kontext:
Moderne Softwaresysteme sind zunehmend dynamisch und in hochvernetzten Umgebungen eingebettet, wodurch sich Vertraulichkeitsanforderungen nicht nur zur Entwurfszeit, sondern auch zur Laufzeit ändern können. Während architekturbasierte Analysen bereits eine frühzeitige Erkennung und Behebung von Vertraulichkeitsverletzungen in Designzeitmodellen ermöglichen, fehlen bislang wirksame Ansätze zum Umgang mit Laufzeitverletzungen. Unsicherheiten durch sich verändernde Kontexte und Systemzustände erschweren die präzise Bewertung und Korrektur solcher Verstöße. Selbstadaptive oder evolutionäre
Systeme versprechen hier Abhilfe, indem sie zur Laufzeit auf Verletzungen reagieren und Anpassungen automatisch vornehmen können. Dennoch mangelt es derzeit an systematischen Methoden, um Vertraulichkeitsverletzungen in Laufzeitmodellen zuverlässig zu erkennen und wirksam zu beheben.
Aufgabenstellung:
Ziel dieser Arbeit ist die Kopplung zweier bestehender Frameworks zur automatisierten Behebung von Vertraulichkeitsverletzungen in Laufzeitmodellen. Ein vorhandenes Verfahren ermöglicht bereits die vollautomatische Korrektur von Vertraulichkeitsverletzungen in Designzeitmodellen, während das iObserve-Framework Laufzeitinformationen/- änderungen in Architekturmodelle integriert. Durch die Verbindung beider Ansätze soll ein Verfahren entstehen, das Vertraulichkeitsverletzungen zur Laufzeit erkennen und selbständig beheben kann. Falls eine automatische Anpassung aufgrund widersprüchlicher Anforderungen nicht möglich ist, soll das System zudem eine manuell geführte Evolution unterstützen, bei der vordefinierte Anpassungsoptionen bereitgestellt werden.
Kontakt
Bei Interesse und/oder Fragen können Sie mich jederzeit kontaktieren. Wir können das Thema gerne weiter besprechen und versuchen, es an Ihre persönlichen Wünsche anzupassen.
Robert Heinrich (Institute Homepage)