
Data-Driven Search and Analysis of Research Software
M.Sc. Florian Sihler
While it is great to see people focusing their life to software engineering and other related fields in computer science, it is important to keep in mind that many of those who have to code or work with code specialize in other domains.
My current research focuses on helping these people with a non-programmer background, using a combination of static and dynamic program analysis. For this, I work on a hybrid dataflow analysis framework for the R programming language called flowR (joint by Oliver Gerstl since October 2025), which is commonly used for statistical analysis. My work received the YoungRSE award at the deRSE24, the award for the best master's degree in the field of computer science at Ulm University, and the Rising Star award at RSECon25. If you are interested, feel free to get in touch with me or check out the flowR repository on GitHub or my portfolio website.
Useful Links
View the poster here (PDF). FlowR is actively developed on GitHub at flowr-analysis/flowr.

View the poster here (PDF). FlowR is actively developed on GitHub at flowr-analysis/flowr.
View the poster here (PDF, LaDeWi '24). You can try the game online at: https://exia.informatik.uni-ulm.de/waddle/.



Teaching
Furthermore, I assist in teaching:
- Bachelor Seminar (WT24/25 [Serious Games], ST25 [Static Analysis])
- Functional Programming (WT22/23, WT23/24, WT24/25, WT25/26)
- Functional Programming 2 (ST24, ST26)
- Grundlagen der praktischen Informatik (WT22/23)
- Objektorientierte Programmierung (ST24, ST25, ST26)
- Softwarequalitätssicherung (WT24/25 [Static Analysis], WT25/26 [Static Analysis])
- Software Engineering/Informatik Projekte (WT23/24 [Code Reconstruction], WT24/25 [Waddle], ST25 [R Projects])
Topics for Theses and Projects
Dynamic and Static Program Analysis

Context
Classical code coverage techniques are widely used to give an indication of the quality of a test suite (with respect to its capability in detecting faults within the system under test).
However, they are not always effective and can be outright misleading [1, 2]. Consider a scenario in which you simply execute code within a unit test but never check whether the resulting state is as expected.
While (at least for most languages) this still ensures that the code does not raise a runtime exception, this is way too weak for most use-cases.
As one possible solution, Schuler and Zeller introduced the concept of checked coverage [3], which uses dynamic slicing to only consider the executed code that contributed to something which is checked with an assertion. Later work by Zhang and Mesbah [4] showed that such checked coverage is indeed a strong indicator of the effectiveness of a test suite.
Research Problem
In this work, we want to look at an alternative to dynamic slicing - static slicing, which does not execute the code and hence over-approximates all potential executions. In contrast to a dynamic slice on an assertion, the static slice contains all the code that could potentially affect the assertion, even if it is not executed in a particular test run. This way, we obtain additional information about the test suite and the system under test, yet we do not know whether this information is useful to gauge the effectiveness of the test suite.
Tasks
More specifically the intended steps of this work are as follows:
- Consider a well-supported language such as Java alongside an appropriate 1) static slicer, 2) dynamic slicer, and 3) coverage tool.
- Use these tools to compute the static and dynamic slices for test-suites of real-world Java projects.
- Analyze, compare, and discuss the results of the static and dynamic slices with respect to the code coverage and the effectiveness of the test suite (e.g., using mutation testing).
Related Work and Further Reading
- H. Hemmati, "How Effective Are Code Coverage Criteria?," 2015 IEEE International Conference on Software Quality, Reliability and Security, Vancouver, BC, Canada, 2015, pp. 151-156.
- Laura Inozemtseva and Reid Holmes. 2014. Coverage is not strongly correlated with test suite effectiveness. In Proceedings of the 36th International Conference on Software Engineering (ICSE 2014). Association for Computing Machinery, New York, NY, USA, 435–445.
- Schuler, D. and Zeller, A. (2013), Checked coverage: an indicator for oracle quality. Softw. Test. Verif. Reliab., 23: 531-551.
- Yucheng Zhang and Ali Mesbah. 2015. Assertions are strongly correlated with test suite effectiveness. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015). Association for Computing Machinery, New York, NY, USA, 214–224.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
Context
Let us assume you are a happy researcher! You just found a great paper that describes an interesting analysis accompanied with several figures illustrating the result. If the results are to be believed, you might want to apply the same analysis to your own data. However, when you try to reproduce the figures (and are lucky enough that the script runs through), you notice that they look different than in the paper. Even though the changes might be minimal in many cases (e.g., different labels, colors, or scales), they can also be more severe with different shapes, missing data points, or even completely different results.
Problem
Given a paper and the accompanying reproducibility package, we want to automatically match the figures in the paper with those best matching those generated by the package, identifying any differences. As a possible extension, we want to identify the section of the code responsible for the figure and guess the reason for the differences (or at least provide the information to the researcher to check).
Potential Tasks
- Research existing approaches for figure comparison and code provenance analysis (e.g., [1,2])
- Implement a prototype for the figure comparison (e.g., using image processing techniques or vector graphics analysis)
- Evaluate the prototype and analyze the results and identify potential reasons for differences (e.g., by tracing back to the code sections responsible for figure generation)
- Link the findings back to the code (e.g., by identifying figure creations in the source code and using program slicing to extract the relevant parts [3])
Related Work and Further Reading
- M. Nuijten and J. Polanin. “statcheck”: Automatically detect statistical reporting inconsistencies to increase reproducibility of meta-analyses
- Standardization of Post-Publication Code Verification by Journals is Possible with the Support of the Community [more specifically CODECHECK]
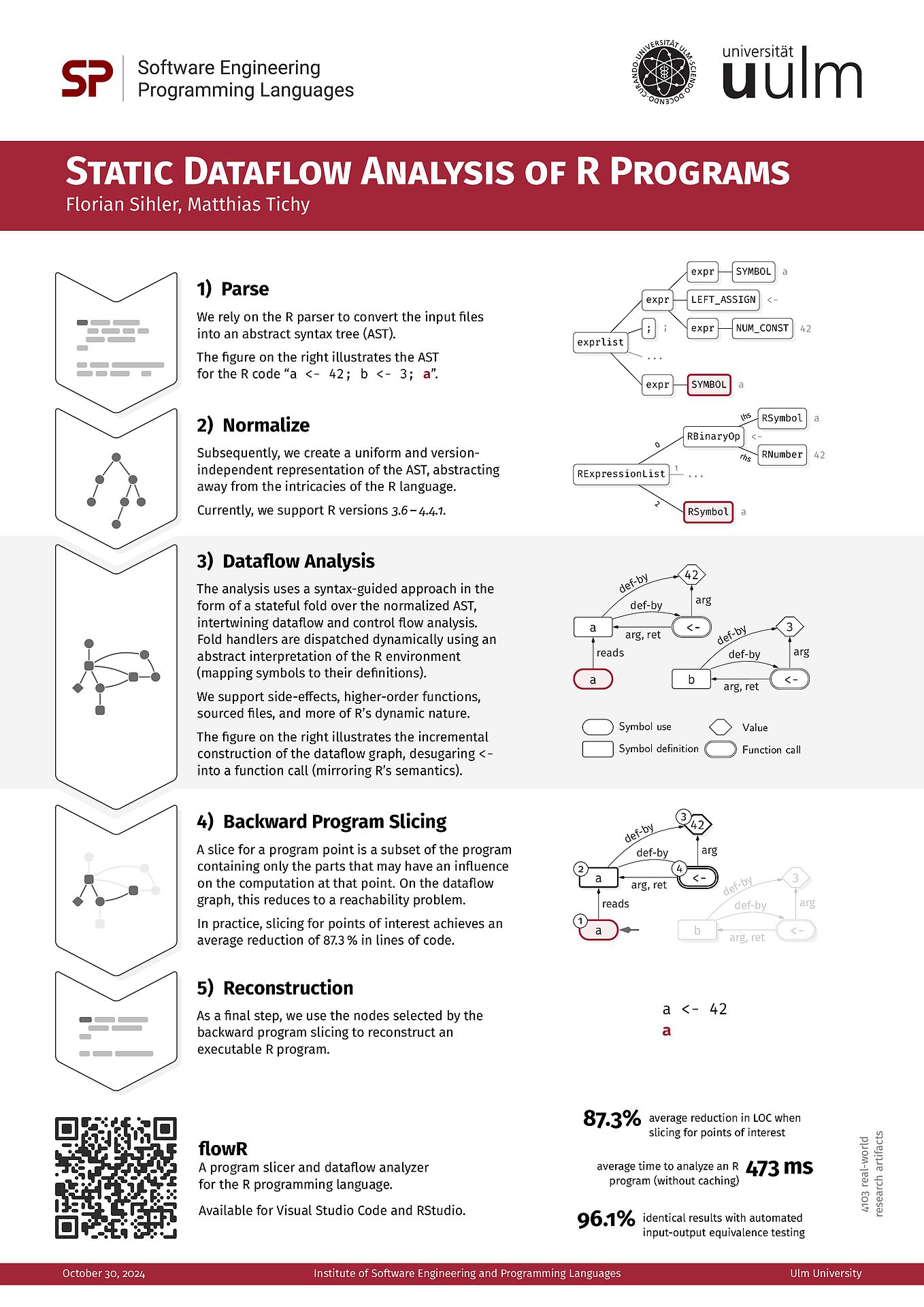
- F. Sihler and M. Tichy. Statically Analyzing the Dataflow of R Programs.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[de] P: Paket-Übergreifende Statische Programm-Analyse (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/bilder/flowR/flowr-project-graphics.png)
[2–6 Students] [AP SE] [PSE1] [PSE2]
Statische Analyse bezeichnet die Untersuchung von Programmen auf Laufzeiteigenschaften ohne diese tatsächlich auszuführen. Sie ist ein integraler Bestandteil moderner Softwareentwicklung und hilft beim Identifizieren von Fehlern, Sicherheitslücken oder dem Verbessern der Lesbarkeit. Compiler verwenden statische Analyse beispielsweise, um Typfehler zu vermeiden oder möglichst optimalen Code zu generieren. Entwicklungsumgebungen oder Language Server verwenden statische Analyse, um Ihre Funktionalität wie Refactorings oder Autovervollständigung zu realisieren (Siehe dazu auch Foliensätze statische Programmanalyse).
In diesem Projekt geht es um die Arbeit an und um flowR, einem Framework für die statische Analyse von R, einer statistischen Programmiersprache die häufig in der Datenanalyse und -visualisierung eingesetzt wird. Eine ausgiebige Analyse des Daten- und Kontrollflusses ermöglicht es flowR beispielsweise ein Programm nur auf die Teile zu reduzieren, die für die Generierung einer Grafik oder die Berechnung eines statistischen Modells relevant sind (das sogenannte Program Slicing) oder mittels Abstract Interpretation die Wertebereiche von Variablen zu bestimmen.
Über flowR
Aktuell kann flowR als Erweiterung für Visual Studio Code, Positron und RStudio, sowie direkt als Docker Image verwendet und ausprobiert werden. Folgende Zeile ermöglicht euch beispielsweise, flowR mit seinem read-evaluate-print loop zu erkunden:
docker run -it --rm eagleoutice/flowr:latest
Wenn ihr dann im REPL zum Beispiel den Datenflussgraph eines R Ausdrucks sehen wollt, könnt ihr folgendes eingeben:
R> :df! x <- 2
Zum Verlassen, genügt ein :q flowR wird unter der GPLv3 Lizenz auf GitHub hauptsächlich in der Programmiersprache TypeScript entwickelt. Die ausführliche Dokumentation erfolgt über ein dediziertes und automatisch aktualisiertes Wiki und direkt im Code.
(Mögliche) Ziele
Dieses Semester ist das Anwendungsprojekt für flowR denkbar flexibel gestaltet und bietet eine Vielzahl an spannenden möglichen Bereichen (die sich so oder so ähnlich auch in Richtung einer Abschlussarbeit ausbauen lassen). Folgende Liste stellt einige mögliche Aufgabenbereichen vor, mit denen Ihr euch in flowR verwirklichen könnt. Die konkrete Zuteilung erfolgt dann zu Beginn des Projekts, je nach Interesse:
- Sicherheitsanalysen — Rs tief verwurzelte, dynamische Natur erlaubt zwar zum einen eine hohe Flexibilität und eine explorative Analyse von Daten, birgt aber auch gleichzeitig zahlreiche Risiken, vor allem wenn R-Code aus unsicheren Quellen ausgeführt wird. Daher möchten wir flowR um klassische Sicherheitsanalysen erweitern um Sicherheitslücken wie Code Injection oder Improper Input Validation zu erkennen.
- Transitive Paket-Analysen — flowR bietet mittlerweile eine fundierte Grundlage um den Daten- wie auch Kontrollfluss von R Skripten aber auch ganzen Paketen zu analysieren (und das ziemlich schnell, so benötigen wir mit 16 Kernen nur etwas mehr als eine Stunde um alle aktuellen Paketversionen zu analysieren). Allerdings verbleiben diese Ergebnisse gerade noch auf der Ebene einzelner Pakete und ignorieren die zusätzlichen Möglichkeiten von Paket-Übergreifenden Analysen, wie beispielsweise das nachverfolgen von Datenflüssen über Paketgrenzen hinweg.
- Dynamisches Laden von Code — Machen wir es kurz, R ist eine wundervolle Sprache. Kein Wunder, dass eine solche Sprache daher auch Möglichkeiten bietet, Code und auch bereits im Voraus berechnete Datensets durch diverse Binärformate dynamisch zu laden. Gerade solche Funktionen stellen allerdings eine große Herausforderung für statische Analysen dar, da der Code und seine Auswirkungen, bzw. die Daten so erst zur tatsächlichen Laufzeit bekannt sind. Gerade für die Fälle, in denen die geladenen Daten oder der Code bereits zur Analysezeit (wenn auch nur teilweise) vorliegen, möchten wir flowR dahingehend erweitern, dass solche dynamisch geladenen Inhalte auch in die Analyse einbezogen werden können.
- Erkennen impliziter Annahmen für externe Daten — Das durchschnittliche Analyse-Skript sieht wie folgt aus: Geladene Daten werden zunächst bereinigt, transformiert und anschließend analysiert oder visualisiert. Dabei werden allerdings häufig implizite Annahmen über die Struktur und den Inhalt der Daten getroffen (z.B. dass eine Spalte nur numerische Werte enthält oder dass keine fehlenden Werte vorliegen). Solche Annahmen können zu Fehlern führen, wenn die tatsächlichen Daten nicht den Erwartungen entsprechen oder sich später ändern. Fehler, welche sich häufig nicht oder nur sehr spät auch bei der Ausführung bemerkbar machen, da sie zwar die diese impliziten Annahmen verletzen, aber dennoch plausibel wirkende Werte produzieren. Mithilfe von flowR wollen wir nun Techniken entwickeln, um solche impliziten Annahmen statisch zu inferieren und in die Analyse einzubetten.
- Erklärbare Datenflussanalyse und API — Statische Programmanalyse ist ein wundervolles Themenfeld mit vielen komplexen Algorithmen und Techniken, die in einem emergenten Zusammenspiel die Analyse auch komplexer Programmsemantiken erlauben. Allerdings führt diese Komplexität auch dazu, dass die Details für Nutzer:innen von statischen Analysen häufig schwer nachvollziehbar sind und selbst vermeintlich einfache APIs eine Reihe an Annahmen Treffen, welche die "einfache" Nutzung erschweren. Hier geht es also darum, die bestehenden Analysen und APIs von flowR so zu erweitern und instrumentieren, dass diese die konkreten Schritte einer Analyse nachvollziehbar machen.
- Quellcode-Transformation — Statische Analyse wird häufig dafür genutzt um Fehler in Programmen zu finden oder Informationen über deren Verhalten zu gewinnen. Allerdings können wir viele Fehler bereits automatisch beheben (wie z.B. mit Quick-Fixes bei Lintern), Programme optimieren oder automatisiert instrumentieren um dann bei Ihrer Ausführung weitere Informationen zu erhalten. Dafür benötigen wir allerdings eine Möglichkeit, den R-Code auf syntaktischer Ebene transformieren und dann wieder zurück in Quellcode übersetzen zu können. Damit soll flowR um ein solches Quellcode-Transformations-Framework (vgl. Spoon) erweitert werden.
Interesse? Dann melde dich doch gerne bei mir und werde Teil des flowR Teams!
Context
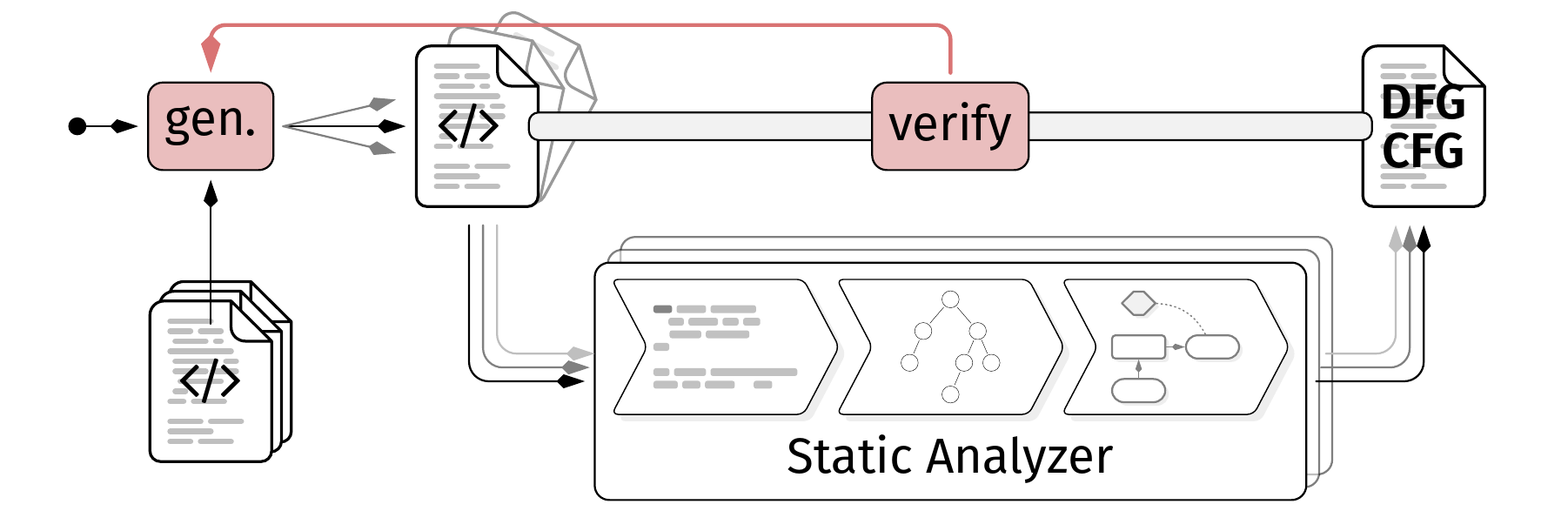
Static program analysis is a wonderful topic and a gigantic area with countless application domains such as optimization, verification, and bug detection. While building such tools is already a challenging task, ensuring that they actually work correctly and provide high-quality results is even more difficult. Modern programming languages ship with complex and ever-evolving features, making it hard to cover all of them correctly. This is made even harder with underspecified and constantly changing language semantics, or languages in which the semantics leave behaviors undefined and up to the implementation (e.g., C/C++). While proofs and formal verification can help to ensure correctness, they usually verify the correctness of the theoretical concept behind the analysis with the theoretical model of the programming language in an idealized environment, not the actual implementation of the analysis tool with all its engineering decisions, optimizations, and quirks on real-world platforms. To compensate this we want to develop techniques to automatically check the correctness and quality of static analysis tools.
Problem
Given a static analyzer such as flowR [1], generate strategies to produce program to analyze (either taken from mutations of real-world sources or synthetically generated [2]) and use them to evaluate the correctness and quality of the analysis results. These strategies can require executable programs to compare the dynamic behavior with the static prediction, or just static code snippets to check for soundness and precision of the analysis (cf. [3]).
Potential Tasks
- Research existing approaches for automatic correctness and quality analysis of static analysis tools (e.g., using metamorphic testing [2])
- Implement a prototype framework to generate input programs for a given static analysis tool (e.g., flowR) and use them to evaluate the correctness and quality of the analysis results, using various strategies.
- Evaluate the effectiveness of the generated test cases in finding issues in the static analysis tool.
Related Work and Further Reading
- F. Sihler and M. Tichy. Statically Analyzing the Dataflow of R Programs.
- Chen T., Kuo F., Liu H. et al. Metamorphic Testing: A Review of Challenges and Opportunities
- An issue summarizing current ideas
If you want to, you can have a first look at flowR for yourself!
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[RESERVED] B/M: Dead/Unused Code Detection for R (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/dead-code-graphic.png)
Context
Dead or unused code describes all parts of a program that are either never executed at runtime or never used in any way.
Such parts hinder not only the readability of the program — requiring users first to realize that such snippets do not actually contribute to the program's functionality — but also the maintainability of the code, as users may be afraid that the code could be used in some way [1, 2].
Additionally, dead code can lead to performance issues, as it may cause the definitions of many unused functions, the loading of unnecessary datasets, or the calculation of values that are never used.
Research Problem
Given an R program and information on its control- and dataflow, identify the dead and unused code within the program adapting well known algorithms to the dynamic nature of the R programming language [3,4,5]. For this, we use a static dataflow analyzer called flowR [6] which provides us with a control flow and a dataflow graph.
Tasks
More specifically, the task are:
- Adapt the dead code elimination problem to the R programming language and discuss which code can be removed safely
- Use flowR's control flow and dataflow graph to identify the dead code using your adapted algorithm
- Evaluate and discuss the effectiveness of your algorithm on a set of real-world R programs
Related Work and Further Reading
- S. Romano, C. Vendome, G. Scanniello and D. Poshyvanyk, "A Multi-Study Investigation into Dead Code," in IEEE Transactions on Software Engineering, vol. 46, no. 1, pp. 71-99, 1 Jan. 2020.
- Simone Romano, Giovanni Toriello, Pietro Cassieri, Rita Francese, and Giuseppe Scanniello. 2024. A Folklore Confirmation on the Removal of Dead Code. In Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering (EASE '24). Association for Computing Machinery, New York, NY, USA, 333–338.
- Jens Knoop, Oliver Rüthing, and Bernhard Steffen. 1994. Partial dead code elimination. In Proceedings of the ACM SIGPLAN 1994 conference on Programming language design and implementation (PLDI '94). Association for Computing Machinery, New York, NY, USA, 147–158.
- Rastislav Bodík and Rajiv Gupta. 1997. Partial dead code elimination using slicing transformations. In Proceedings of the ACM SIGPLAN 1997 conference on Programming language design and implementation (PLDI '97). Association for Computing Machinery, New York, NY, USA, 159–170.
- I. Malavolta et al., "JavaScript Dead Code Identification, Elimination, and Empirical Assessment," in IEEE Transactions on Software Engineering, vol. 49, no. 7, pp. 3692-3714, July 2023.
- github.com/flowr-analysis/flowr
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[RESERVED] B/M: Automatically Infer Code-Constraints (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/bilder/flowR/code-contracts.png)
Context
Let's suppose you are a data scientist tasked with the analysis of a dataset. As an expert of the domain you have a quick look at the dataset and remember an older script by a colleague which already loads, prepares, and transforms the dataset as you want! Reusing it just leaves you with the task of visualizing the data (as is the common workflow) so you quickly write up and run the script... and luckily realize that even though the script runs and produces figures eerily close to what you would expect, something is not right. The dataset of your colleague never contained a zero so the script contains the implicit assumption of being just able to divide cells.
Within this work we want to make such implicit assumptions explicit in the code, alerting users whenever they no longer hold!
Problem
You have an R script together with the statically inferred dataflow graph that informs you about the control and data dependencies of function calls, variables, and definitions in the program.
The challenges are to
- identify points of interest at which the behavior of the program is defined,
- infer contracts that represent the potential implicit assumptions at the given position (e.g., that the value of a variable has to be non-zero, smaller than the length of another vector, ...), and
- instrument the code to automatically verify these constraints from now on.
Of course, the specific scope of these challenges as well as the focus depends on whether you want to do this as a bachelor's or master's thesis as well as your personal preference.
Tasks
- Enrich flowR [4], a dataflow analysis framework for the R programming language, with the capability to infer predefined constraints
- Create an initial collection of sensible constraints to infer (e.g., non-zero values, ...)
- Infer these constraints and instrument the program to reflect them [5]
One way to infer such constraints would be the definition of abstract domains [1] although classical optimization techniques such as constant folding and constant propagation help as well [2, 3].
Related Work and Further Reading
- P. Cousot. Principles of Abstract Interpretation. (ISBN: 978-0-26-204490-5)
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- B. Meyer, Applying "Design by Contract"
If you want to, you can have a first look at flowR for yourself: https://github.com/flowr-analysis/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
Supervised and Completed Theses
Master Theses

In this thesis, we propose a theoretical concept and a proof-of-concept implementation to infer the shape of data frames in R programs using abstract interpretation.
R is a programming language widely used in data science and statistical programming that is mostly used by people without a background in computer science. However, there is a lack of sufficient static code analysis tools for R. One of the most important data structures in R is the data frame which is used to store, transform, and visualize data in R scripts.
Therefore, we provide the theoretical concept and a proof-of-concept implementation to track the shape of data frames in R programs using abstract interpretation. We identify data frame operations and transformations that are relevant to track shape information about data frames, define a formal concept to abstract the concrete semantics of the data frame operations, discuss the implementation of the abstract interpretation of data frame shapes, and evaluate our implementation on a large set of real-world R scripts.
We first identify relevant data frame operations by analyzing the most commonly used data frame functions in R scripts and R packages. Then, we define the abstract domain to track the shape of data frames in R programs. We abstract the concrete data frame functions to abstract data frame operations to describe the abstract semantics of these abstract operations with respect to shape constraints for the data frames. Based on the theoretical concept, we develop an implementation of the abstract interpretation of data frame shapes in flowR, an open-source static analyzer for the R programming language. Using the implementation, we provide a query to retrieve the shape of data frames and a linter rule to validate accessed columns and rows of data frames in R. Finally, we evaluate our implementation on a set of labelled real-world R scripts with a ground truth to analyze the correctness and accuracy of our implementation, and perform a large-scale evaluation on 33 314 real-world R scripts to determine how many constraints can be inferred by our implementation and measure the runtime performance of the implementation.
The supported features of our concept and implementation are limited, as there are many different data frame functions in R with many edge cases. Moreover, there is no formal definition of the operational semantics of R and most semantics are defined implicitly. As the scope of this thesis is limited, we focus on a subset of data frame operations identified based on the most common data frame functions in R scripts and R packages. Our implementation was correct for all points of interest of the evaluated labelled R scripts. We inferred data frame shapes for 73.4 % of the evaluated points of interest that represent data frames. Of the total number of 33 314 real-world R scripts, our implementation inferred data frames shapes for 66.9 % of all scripts. In total, we inferred data frame shape constraints for 406 890 data frame expressions with partial shape information for 34.1 % and full shape information for 2.6 % of the data frame expressions. Our implementation required, on average, 4.16 s with high outliers and a median of 209 ms. The average runtime of the total analysis, including the parsing, data flow graph construction, and control flow graph generation, was 4.9 s with a median of 598 ms. We consider the median total runtime of 598 ms to be fast enough for most use cases.
In this master thesis we describe the development and evaluating of a tool that tries to re-engineer R research scripts into a Software Product Line.
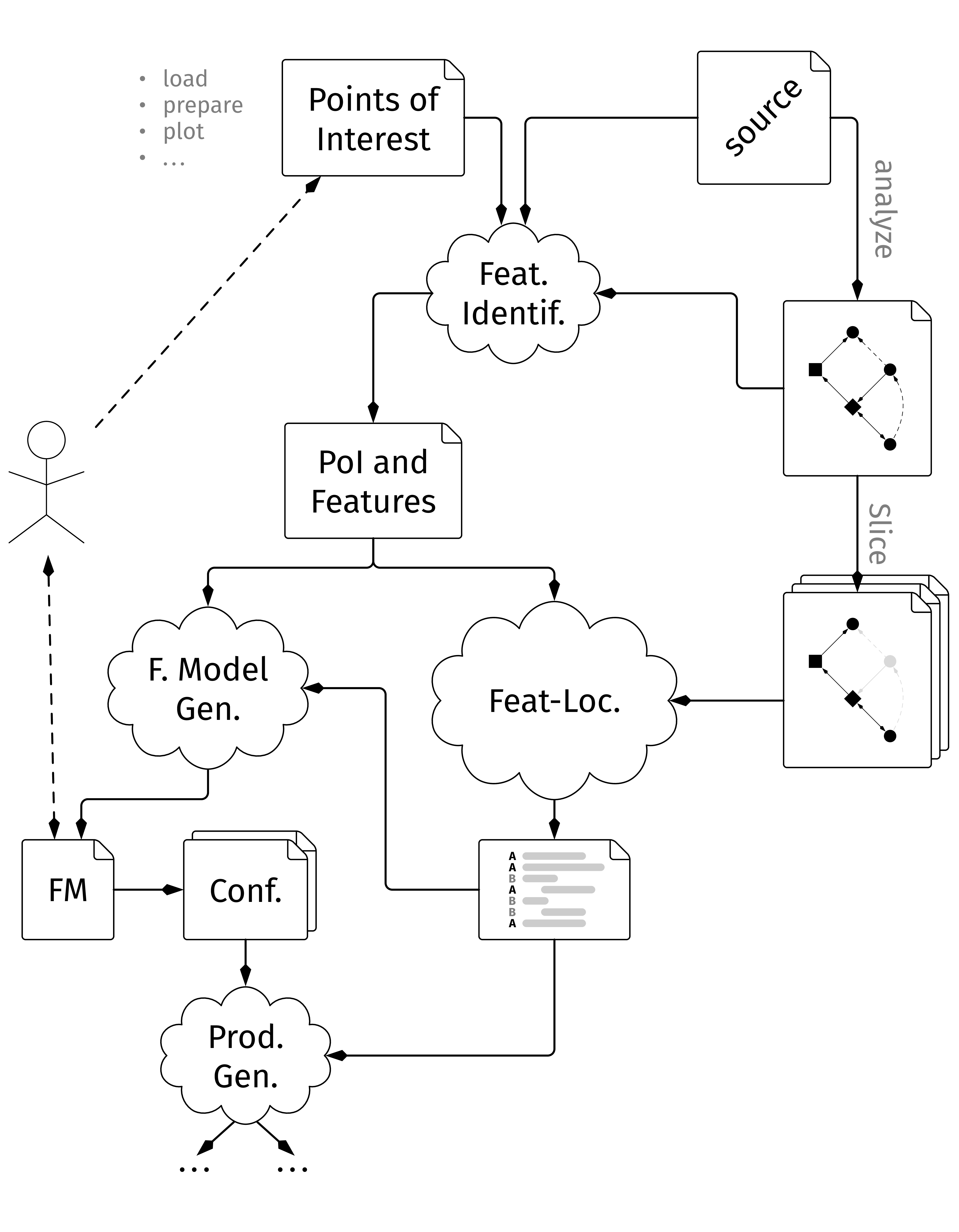
R research scripts are rarely reproducible and a different user might have a hard time comprehending a badly structured script. This creates the need for tools to support them in understanding which plot was created through which chain of actions. Going even further, some aspects of the given R research script might be reusable for a new task, but finding them is not simple, so the tool should be able to analyze the script once and then create a representation where those aspects can be marked and selected.
We propose GardenR a tool to transform a R research script by detecting Points of Interest, locating them in the source code, create dependencies for interactions with other features and annotate them in the source code through feature flags. Alongside GardenR, we collect a set of Points of Interest for the data science domain of the R programming language and use them to evaluate our tool.
First, we conceptualize the algorithms needed for the identification, localization and visualization of Points of Interest in research scripts. Then we implement those concepts, focusing on architectural decisions and specifics regarding the R programming language in particular as well as the collection of Points of Interest through labeling the exposed functions of R packages. Next, we benchmark the tool using real-world code examples.
The capabilities of our tool are currently limited due to a not fully functioning process, with the annotation of the source code creating errors during the execution. Furthermore, there exists a memory leak in the tool, which is mitigated by restarting the tool upon triggering a death flag.
We identify 12 004 functions that can be mapped to the data science process. Furthermore, our benchmarking of GardenR was able to analyze 958 out of 1 000 real-world R research scripts, detecting a median of 91 features per instance and a median increase by factor 1.29 in lines of code. Without the tool creating executable scripts, we were unable to confirm the correctness of our approach against a outputs of the source, but used tests, sanity checks and manual labeling that were compared to the results of the execution to mitigate this.
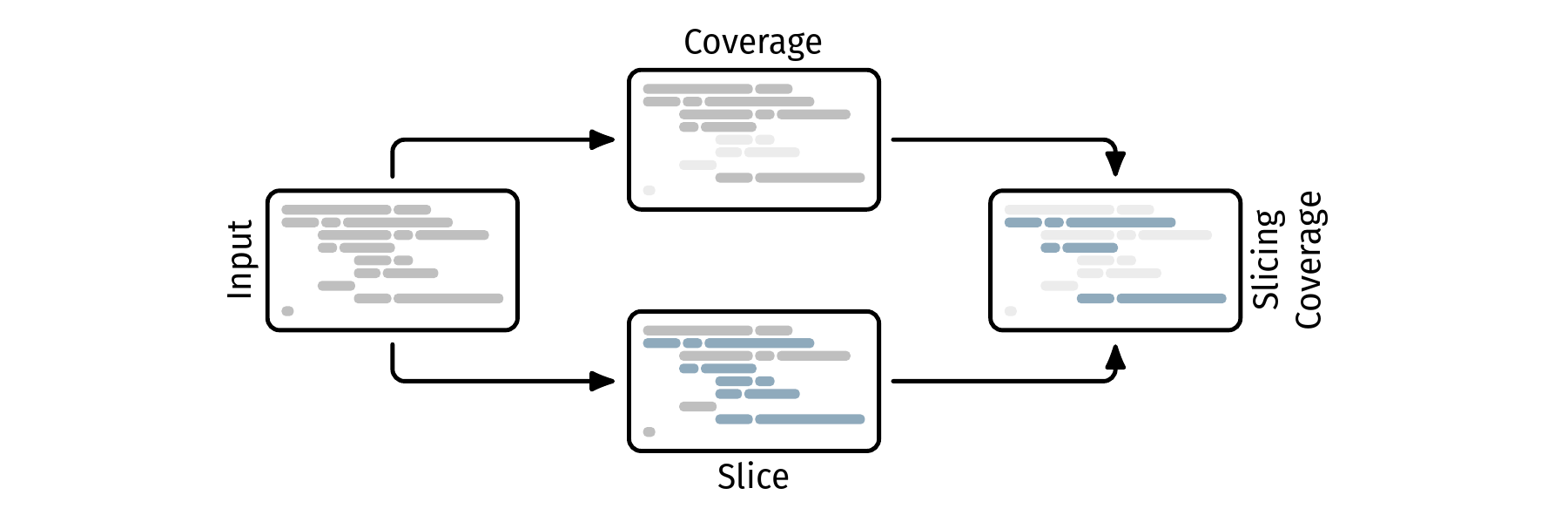
This thesis covers the development and evaluation of a novel way to determine coverage scores for the R programming language. We calculate a static backward program slice for all assertion criteria of a given test suite and use this information together with coverage information to determine the coverage of the tested code.
Testing software is a crucial part of the development process. However, determining when the software is sufficiently tested is an impossible task. Code coverage metrics aim to be a decision-making aid in this regard. But research shows, that they can be deceptive and in fact do not necessarily reflect the quality of a testsuite.
We propose slicing coverage as a novel approach that aims to enhance the accuracy of coverage scores by calculating them based on the program slice resulting from the test’s assertion criteria. We also provide a proof-of-concept implementation for the R programming language. Alongside the theoretical concept and a practical implementation, we evaluate our approach on a set of real-world R packages to demonstrate its potential benefits.
To calculate slicing coverage, we combine regular coverage information with the result of a static backward program slice for all assertions. This way, we can exclude code that was executed but had no influence on the test’s outcome, or in other words: code that was not checked by a assertion. To evaluate slicing coverage, we use two distinct experiments that i) record both slicing coverage and regular coverage scores, as well as execution time and memory usage, and ii) calculate the accuracy of slicing coverage by deliberately inserting faults into a program and measuring how many the test suite is able to detect.
Despite its potential benefits, slicing coverage’s results are inherently limited by the quality of the program slicer and coverage tool used. We also carry over some limitations of traditional coverage metrics like the inherent performance overhead. Besides those conceptual limitations, we also face practical challenges like our implementation being unable to handle implicit assumptions that are not directly encoded in the source or test code.
We find that, for the median package, the traditional and slicing coverage scores differ by 19.53 %, with the slicing coverage score being lower. The median slicing coverage score over all packages lies at 44.09 %.
With regards to memory usage, we deem our slicing coverage implementation to not be a burden on the user’s system, as, for the median package, our implementation only required 384.36 MB of memory. The maximum required memory peaked at 2.11 GB . With regards to the execution time, we come to a different conclusion. The median is, again, reasonable with 85.46 s. However, the average and maximum of 35.01 min and 11.74 h respectively show that there are outliers that require a significant amount of time.
With regards to slicing coverage’s accuracy, we find that mutants introduced in covered code are detected more often than mutants inside the program slice (p = 0.0212). This indicates that slicing coverage’s accuracy is lower than traditional coverage.
Bachelor Theses

In this thesis, we explore and implement string inference for the R programming language using abstract interpretation.
Context: R is widely adopted in the scientific community for data-analysis and visualisation. It allows for a high degree of dynamism, which is often relied upon by its users. This is demonstrated by the prominent use of the eval primitive, which allows executing runtime strings as code. Excessive use of eval exposes users to a variety of pitfalls as it can execute arbitrary code without a static analysis tool being able to properly help.
Objective: We aim to address this situation by empowering static analysers to reason about the flow of strings throughout the program. The gained information about the value-domain of string expressions can be used to determine or approximate the side-effects dynamic operations like eval, assign, and read.csv incur. We proposed a solution consisting of a theoretical concept and a prototype implementation on top of the flowR static analyzer.
Method: We choose three abstract domains, the constant, constant-set, and presuffix domain. They can represent strings by equality, being part of a set, or its prefix and suffix respectively. We define known semantics of R functions as abstract operations for each domain and use them to determine, over-approximating where needed, abstract values for expressions within a script. At the core of our implementation, expression relations are represented as a directed graph, allowing for efficient update propagation. We traverse a script’s AST and assign relevant values an abstract operation node. If a value’s result depends on another value, that relation is captured as an edge. The resulting graph resembles constraints on the domains of the expressions, which we solve by iterating over the nodes and propagating updates to its dependers.
Limitations: The analysis is tailored towards scalar string values and cannot handle other data types like numbers and vectors. This deficiency significantly limits our ability to infer strings in cases where they are employed. Manual analysis has shown that a common pattern for dataset-loading in the R world makes use of both and as a result, hinders our success in these cases. Furthermore, we cannot guarantee correctness in all cases for our presuffix domain due to the recycling rules for vectors and our inability to differentiate between them and single values.
Results: We evaluated our approach using two different datasets. 77 deterministic and executable scripts are executable and were used to build a ground-truth to verify our implementation against. The presuffix domain was able to infer correct values other than top for 79.6% of the instrumented expressions. Within this smaller dataset, no incorrect values were inferred. Out of the 33,314 files of the other dataset, a total of 563 resulted in timeouts or unknown errors during analysis. Across the rest of them, 20.8% of expressions were inferred to be exactly one known string, whilst 37.3% could be inferred partially — meaning that only a part of the string is known. Added up, a total of 58.1% expressions were assigned a non-top value. This may not be as much as the first dataset, but the vastly increased script count paints a more representative picture.
R is a programming language that is widely used in data analysis and statistical computing. While the flexibility granted by its highly dynamic execution model enables effortless exploration and transformation of data, contributing to its popularity among statisticians, the lack of static types and other code validation mechanisms makes writing larger R programs error-prone and hard to maintain.
We aim to address the challenges posed by the lack of static types in R by introducing a static type system and interprocedural type inference algorithm. The proposed solution, consisting of a theoretical framework and practical prototype implementation, seeks to infer accurate and informative types for expressions in R programs, while remaining lightweight and easy to integrate into existing codebases, without relying on type annotations by the user.
Our type inference system is designed on a theoretical level to handle a wide range of R’s dynamic features and type constructs, including expressive types for functions, lists, and vectors, as well as type unions and intersections to account for polymorphism, while also integrating empirical type signatures extracted from real-world R packages to improve precision. It is implemented as extension to the static analyzer flowR and builds upon the type inference approach by Parreaux to infer types through the resolution of subtyping constraints while leveraging flowR’s dataflow analysis capabilities.
While our approach is accurate for a wide range of expressions in R programs, it has limitations in handling certain dynamic features of the language, such as nonstandard evaluation and object-oriented programming features. Therefore, we rely on a set of assumptions about the code being analyzed, which we assume to hold with or without our knowledge. Furthermore, the precision of inferred types is heavily dependent on the inherently limited coverage of the empirical type signatures used in the analysis.
The correctness of our type inference system is ensured through a comprehensive set of 128 unit tests covering all inference rules and key components of our implementation with a statement coverage of 83 %. Additional evaluations on a set of 78 deterministic real-world R scripts indicate that our type inference system is capable of inferring accurate types in 40 % of cases, while incorrect results are inferred in 41 % of cases. However, when not relying on dynamically extracted type signatures to improve precision, the number of incorrectly inferred types reduces to a single case while 16 % of types can be correctly inferred, revealing the limitations of our signature datasets. In a separate performance evaluation on a sample of 1000 scripts, we observe a median inference time of 791 ms per script with 62 % of scripts being processed in under 1 second, demonstrating the potential of typeR for interactive type checking in R development. Note, however, that this time only accounts for type inference and not flowR’s dataflow analysis, which is performed as a prerequisite for our analysis.

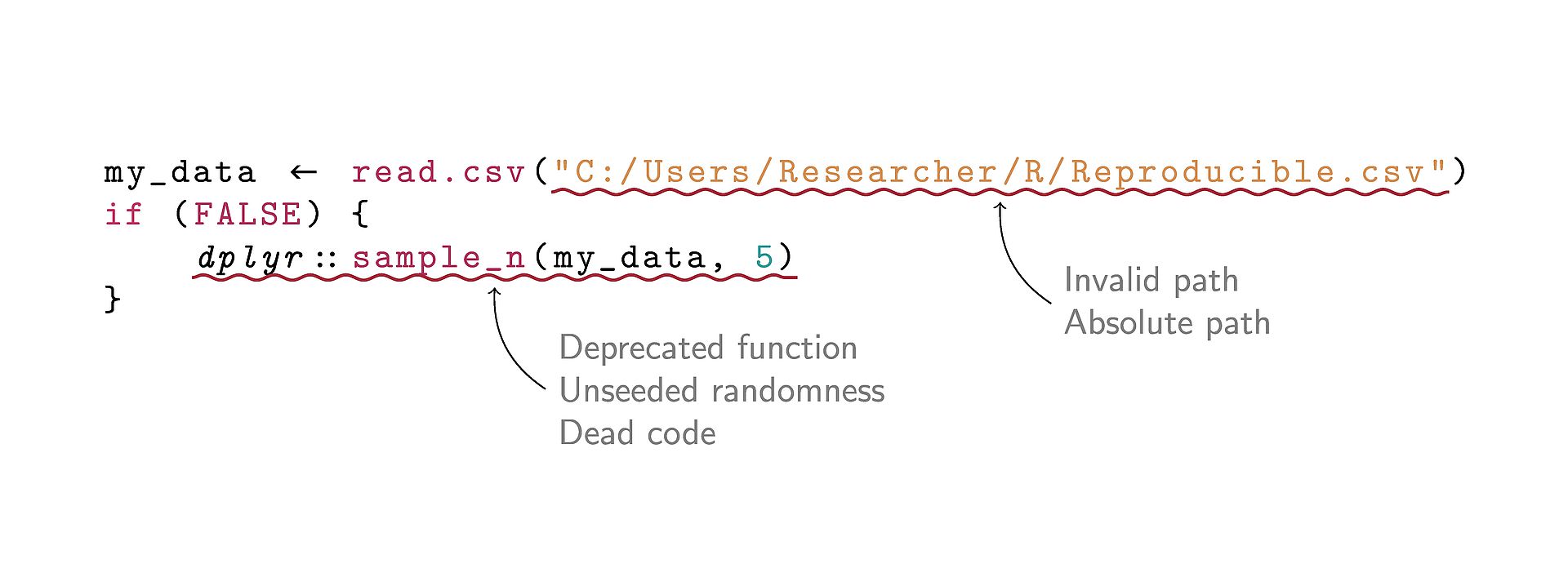
In this bachelor’s thesis, we develop a query language which allows analyzing semantic information extracted from R scripts. We create an extendable linting framework with the help of our query language and implement and evaluate the performance of four reproducibility-focused linting rules.
The R programming language is frequently used in data science research, where R scripts are included as part of reproducibility packages to replicate researchers’ findings. In many cases, such scripts fail to complete without errors or do not replicate the findings described in their accompanying research. In addition, there is a lack of tools that support developers in the creation of reproducible R scripts.
We describe and implement a query language which can be used to implement reproducibility-focused linting rules as part of flowR. Specifically, we select common reproducibility issues, which we remedy through a set of linting rules created with the help of the query language. We then evaluate the linter based on multiple criteria on a set of real-world R scripts.
We propose and implement a set of query language operations in the form of query generators and subsequent transformers. Further, we implement a linting framework that uses the query language to detect and output issues in R scripts. Using the linting framework, we implement four linting rules for reproducibility issues inspired by related tools and frequently found in the literature. Then, we evaluate the correctness and performance of the query language and our linting rules through 341 unit tests as well as a combination of automatic performance measurements and manual spot-checks on an extensive dataset of real-world R scripts.
This work focuses on the implementation and validity testing of the query language, linting framework and our rules, and does not account for whether the rules are considered helpful to users. Additionally, our linter’s usability is limited to commandline interaction and does not yet expose editor functionality.
We find that our query language is practical for the creation of complex linting rules based on a combination of simple query operations. Executing our linting framework on a dataset of 35 373 real-world R scripts, we find that our linting rules return frequent matches in practice, with only 13 % of files containing no match. Our evaluation additionally shows that our linter requires a median time of 695 ms, with the average time of 7 259 ms being heavily affected by outliers in the form of very large scripts in our dataset.

In this bachelor’s thesis, we explore the use of Large Language Models (LLMs) to search for semantic errors in a given R file. We aim to investigate the effectiveness of LLMs in linting for semantic errors and examine their advantages and disadvantages.
In today’s digitalized world, programming is becoming increasingly essential, especially for non-domain experts. Researchers in different kinds of study areas need to analyse their data reliably. Therefore, they create their own programs. The development process of these programs can be supported by various tools, such as linters, to identify errors in the created programs. Yet, creating such linters is challenging and requires a lot of work, especially for problems that require a semantic understanding of a specific domain. We aim to investigate whether LLMs can narrow this gap by finding these errors without requiring complex linter rules.
Our goal is to construct a model that can identify what we call high level error types, like a wrong statistical test method error, which are too complex for typical static analysis tools. We want to achieve this by prompting a LLM to find them. The advantage of this method is that we can simply explain the error in natural language and tell the LLM to search for it. Therefore, we do not need to create a complex linter rule, which requires a lot of work, such as analyzing the structure of data frames.
To analyze the capabilities of this method, we first conduct a prestudy to determine the optimal setup for prompting an LLM to identify errors in an R file. In addition to the high level error types, the model should identify what we call low level error types, which can be detected by typical static analysers. As ground truth for these errors, we use lintr. To analyse the model, we let it search for three low level and two high level error types in a total of about 12 500 randomly selected R files from a dataset of more than 33 000 files. The found low level errors are then automatically compared to found instances by the R linter lintr, whereas the high level ones are compared to placed errors in modified files. Moreover, a subset of the found errors is checked manually.
In the described analysis, we only test the models ’s capabilities for the five selected error types and only for the programming language R. We do not know whether the setup works similarly for other error types and programming languages.
We observe that the capabilities of our created model, which utilizes zero-shot learning, and a code snippet of 50 lines as the context size, are limited. We compare its performance, when using Llama3.1:70b and ChatGPT 4o-mini as LLM; however we do not see too big differences. For the evaluation, we use a ground truth of automatically placed errors with a modified version of mutation testing, and found errors by lintr. The comparison reveals, that our model does not even find every 10th error, which we consider to be insufficient. Its precision is better; however, compared to other static analysers the results are again not satisfactory. However, not all error types perform this poorly. We observe a trend where low level error types perform worse than the high level ones, and conclude that our created model is not a possible replacement for lintr. For high level error types that perform well, however, it can be a useful tool, especially since no other tool is known to us that can identify them. Therefore, a hybrid approach to find all error types could be a successful solution.

In this bachelor thesis, we describe an algorithm for field-sensitive pointer analysis using the R programming language as an example.
While there have been numerous implementations of pointer analyses for languages such as C, C++, or JavaScript, R lacks such comprehensive support. The frequent use of composite data structures and subsetting operators in R suggests a high degree of applicability for field-sensitivity.
The described algorithm handles storing, managing, and reading pointer information. This information is used to manipulate the data flow graph in order to achieve field-sensitivity.
We first elaborate a concept that we then apply to the flowR data flow framework. Afterward, we evaluate the artifact by running a sophisticated pipeline that uses two variants of flowR, one with pointer analysis enabled and one without.
Our implementation’s capabilities are limited by the language subset that we support. In this thesis the support includes the constant definitions of atomic vectors and lists, and subsetting with constant arguments. The approach was designed to increase support for R, and we cannot apply the described algorithm to languages that treat pointers inherently differently.
Our results show that our algorithm provides a solid proof of concept, while our implementation yields a slightly greater slicing reduction for the number of normalized tokens of 82.42 ± 15.59 %, a tolerable runtime increase of 13.81 ms in the median, and a doubling in data flow graph size on average.
Publications
2026
13.
Sihler,
Florian;
Pfrenger,
Lars;
Gerstl,
Oliver;
Tichy,
Matthias
Towards Automatically Inferring Constraints to Identify Implicit Assumptions in Data Analysis
2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE-NIER ’26)
2026
Towards Automatically Inferring Constraints to Identify Implicit Assumptions in Data Analysis
2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE-NIER ’26)
2026
| DOI: | 10.1145/3786582.3786806 |
2025
12.
Sihler,
Florian;
Tichy,
Matthias
Statically Analyzing the Dataflow of R Programs
Proceedings of the ACM on Programming Languages, OOPSLA 2025, Seite 1034-1062
Oktober 2025
Statically Analyzing the Dataflow of R Programs
Proceedings of the ACM on Programming Languages, OOPSLA 2025, Seite 1034-1062
Oktober 2025
| DOI: | 10.1145/3763087 |
11.
Straub,
Raphael;
Sihler,
Florian;
Torbati,
Ali;
Wang,
Cong;
Groner,
Raffaela;
Klös,
Verena;
Tichy,
Matthias
Explainability in Self-Adaptive Systems: A Systematic Literature Review
Euromicro Conference on Software Engineering and Advanced Applications 2025,
September 2025
Explainability in Self-Adaptive Systems: A Systematic Literature Review
Euromicro Conference on Software Engineering and Advanced Applications 2025,
September 2025
| DOI: | 10.1007/978-3-032-04200-2_19 |
10.
Sihler,
Florian;
Pietzschmann,
Lukas;
Straub,
Raphael;
Tichy,
Matthias;
Diera,
Andor;
Dahou,
Abdelhalim
On the Anatomy of Real-World R Code for Static Analysis (Extended Abstract)
Herausgeber: Gesellschaft für Informatik, Bonn
Februar 2025
On the Anatomy of Real-World R Code for Static Analysis (Extended Abstract)
Herausgeber: Gesellschaft für Informatik, Bonn
Februar 2025
| DOI: | 10.18420/se2025-27 |
2024
9.
Sihler,
Florian;
Tichy,
Matthias
flowR: A Static Program Slicer for R
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Tool Demonstrations)
Oktober 2024
flowR: A Static Program Slicer for R
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Tool Demonstrations)
Oktober 2024
| DOI: | 10.1145/3691620.3695359 |
| Weblink: | https://github.com/flowr-analysis/flowr |
8.
Sihler,
Florian
Improving the Comprehension of R Programs by Hybrid Dataflow Analysis
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Doctoral Symposium)
Oktober 2024
Improving the Comprehension of R Programs by Hybrid Dataflow Analysis
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Doctoral Symposium)
Oktober 2024
| DOI: | 10.1145/3691620.3695603 |
| Weblink: | https://dl.acm.org/doi/abs/10.1145/3691620.3695603 11.11.2024 |
7.
Neumüller,
Denis;
Sihler,
Florian;
Straub,
Raphael;
Tichy,
Matthias
Exploring the Effectiveness of Abstract Syntax Tree Patterns for Algorithm Recognition
4. International Conference on Code Quality (ICCQ)
Juni 2024
Exploring the Effectiveness of Abstract Syntax Tree Patterns for Algorithm Recognition
4. International Conference on Code Quality (ICCQ)
Juni 2024
| DOI: | 10.1109/ICCQ60895.2024.10576984 |
| ISBN: | 979-8-3503-6646-4 |
| Weblink: | https://ieeexplore.ieee.org/document/10576984 |
6.
Sihler,
Florian;
Pietzschmann,
Lukas;
Straub,
Raphael;
Tichy,
Matthias;
Diera,
Andor;
Dahou,
Abdelhalim
On the Anatomy of Real-World R Code for Static Analysis
21st International Conference on Mining Software Repositories (MSR '24)
Januar 2024
On the Anatomy of Real-World R Code for Static Analysis
21st International Conference on Mining Software Repositories (MSR '24)
Januar 2024
| DOI: | 10.1145/3643991.3644911 |
| Weblink: | https://arxiv.org/abs/2401.16228 |
| Datei: |
2023
5.
Diera,
Andor;
Dahou,
Abdelhalim;
Galke,
Lukas;
Karl,
Fabian;
Sihler,
Florian;
Scherp,
Ansgar
GenCodeSearchNet: A Benchmark Test Suite for Evaluating Generalization in Programming Language Understanding
GenBench 2023 Workshop
Oktober 2023
GenCodeSearchNet: A Benchmark Test Suite for Evaluating Generalization in Programming Language Understanding
GenBench 2023 Workshop
Oktober 2023
| DOI: | 10.48550/arXiv.2311.09707 |
4.
Sihler,
Florian
Constructing a Static Program Slicer Specifically for R Programs
Masterarbeit
University of Ulm, Germany
August 2023
Constructing a Static Program Slicer Specifically for R Programs
Masterarbeit
University of Ulm, Germany
August 2023
| DOI: | 10.18725/OPARU-50107 |
M.Sc. Florian Sihler

M.Sc. Florian Sihler
Research Assistant
Ulm University
Institute of Software Engineering and Programming Languages
Albert-Einstein-Allee 11
Institute of Software Engineering and Programming Languages
Albert-Einstein-Allee 11
89069 Ulm
Germany