Projektvorstellung
Die Projektvorstellung der Projekte im SoSe 26 fand am Dienstag, 10.02.2026 statt.
Über folgenden Link können Sie die Aufzeichnung ansehen:
Auf dieser Seite werden ab dem 06. Februar 2026 kurz die im SoSe 2026 angebotenen Projekte beschrieben. Es wird dabei nicht zwischen Bachelor und Masterprojekten unterschieden, da wir gemischte Gruppen zu lassen.
Wenn Sie im nächsten Semester eines der unten stehenden Projekte belegen möchten, senden Sie bitte bis zum 25.02.26 eine E-Mail mit priorisierten Wünschen (3-5 Projekte) an Alexander Raschke.
Bitte auch die Buchstaben zur eindeutigen Kennzeichnung in der Mail mit angeben!
Bei Fragen zu den Projekten wenden Sie sich bitte ebenfalls an Alexander Raschke.
Eine Galerie der bisherigen Projekte finden Sie hier: Bisherige SE-Projekte
Die Projektvorstellung der Projekte im SoSe 26 fand am Dienstag, 10.02.2026 statt.
Über folgenden Link können Sie die Aufzeichnung ansehen:
A: Unterstützung der Münsterbauhütte bei Kartierungsarbeiten
B: Votura - Open Source Voting System für Gremienwahlen
C: BlockchainBench - An extensible Tool for Modelling and Analysing Blockchain Systems
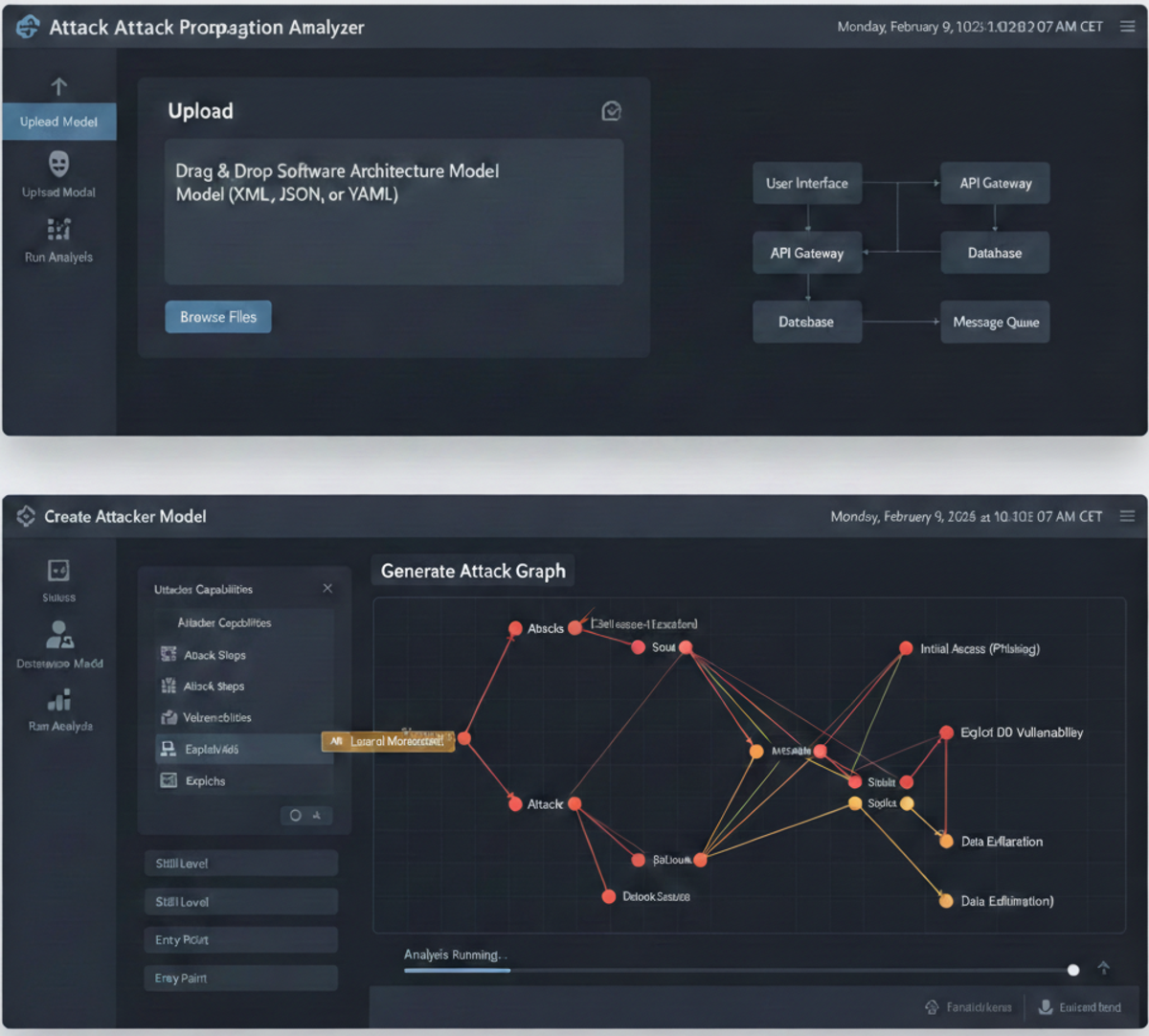
D: Online Modelling and Analysis Tool to investigate Attack Propagation in Software Architectures
E: Statische Programm-Analyse für Projekte
F: Virtual X-Ray – Real-Time Augmented Anatomy Visualization
G: Weiterentwicklung eines LLM-basierten Chatbots zur Generierung von BPMN 2.0 Prozessmodellen
H: GRIPL
I: RPA 2 APA - From Robotic Process Automation to Agentic Process Automation
J: Six-Minute Walk Test (6MWT)
K: Entwicklung eines Control-Dashboards für einen VR Vehicle-Motion-Simulator
L: Moment – An Open Source Lightweight Meta-Modeling Framework
M: Build your own SaaS - and automate it!
N: WebXR-Client for 3D-Workroom
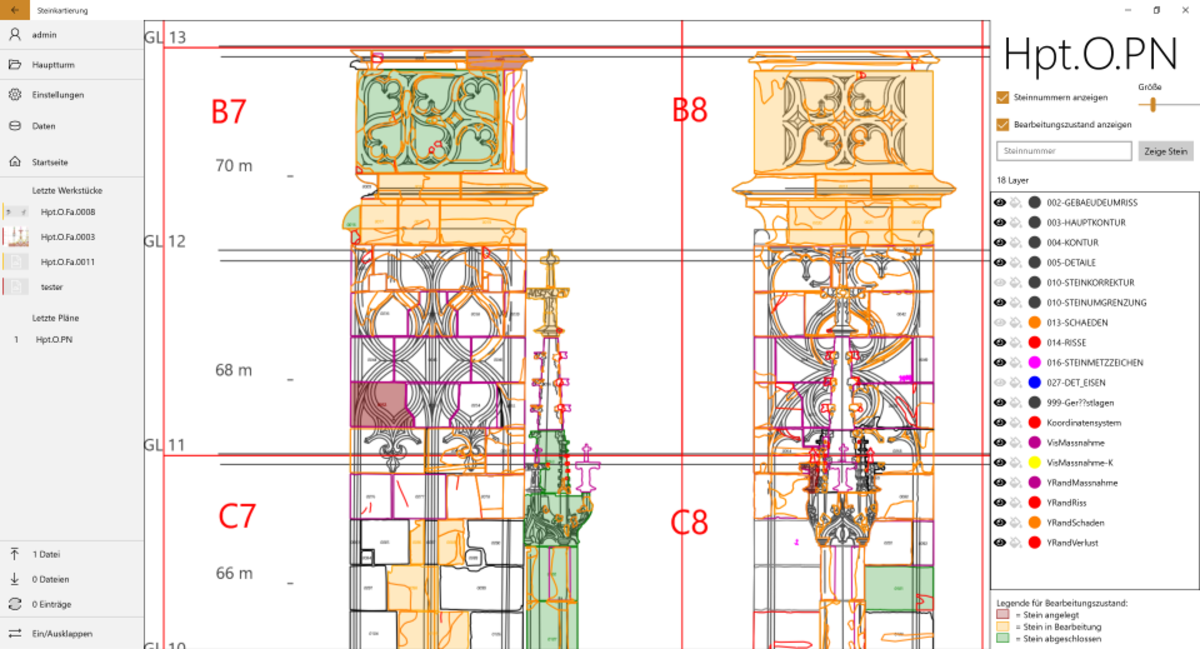
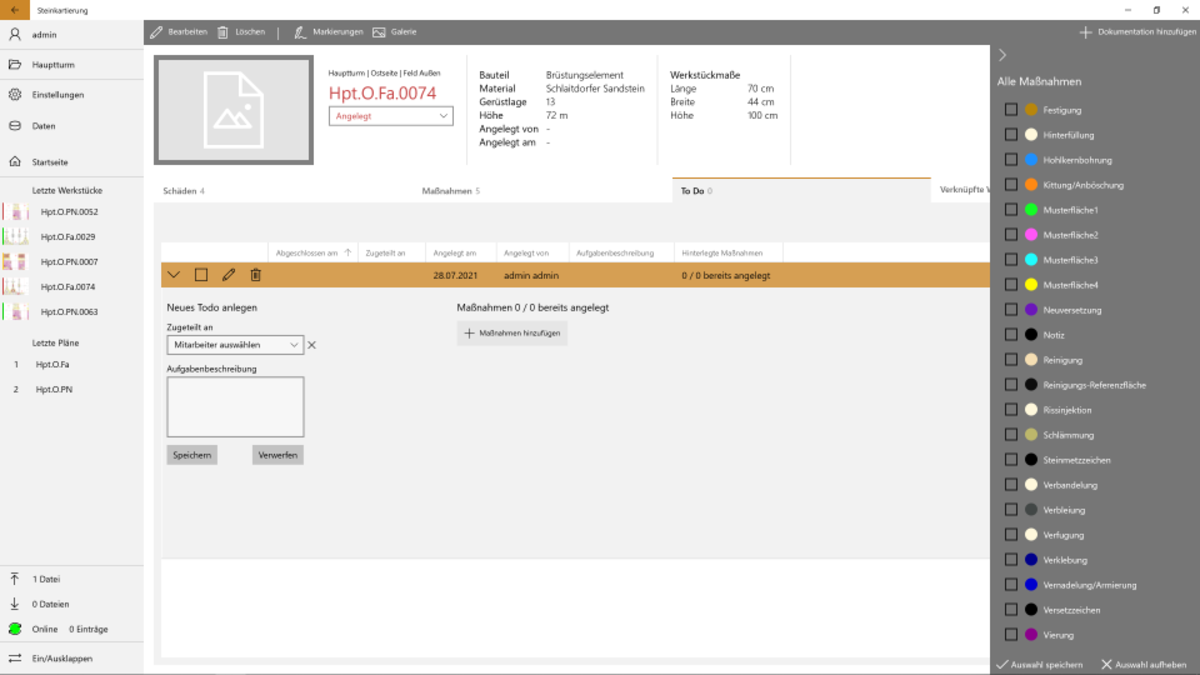
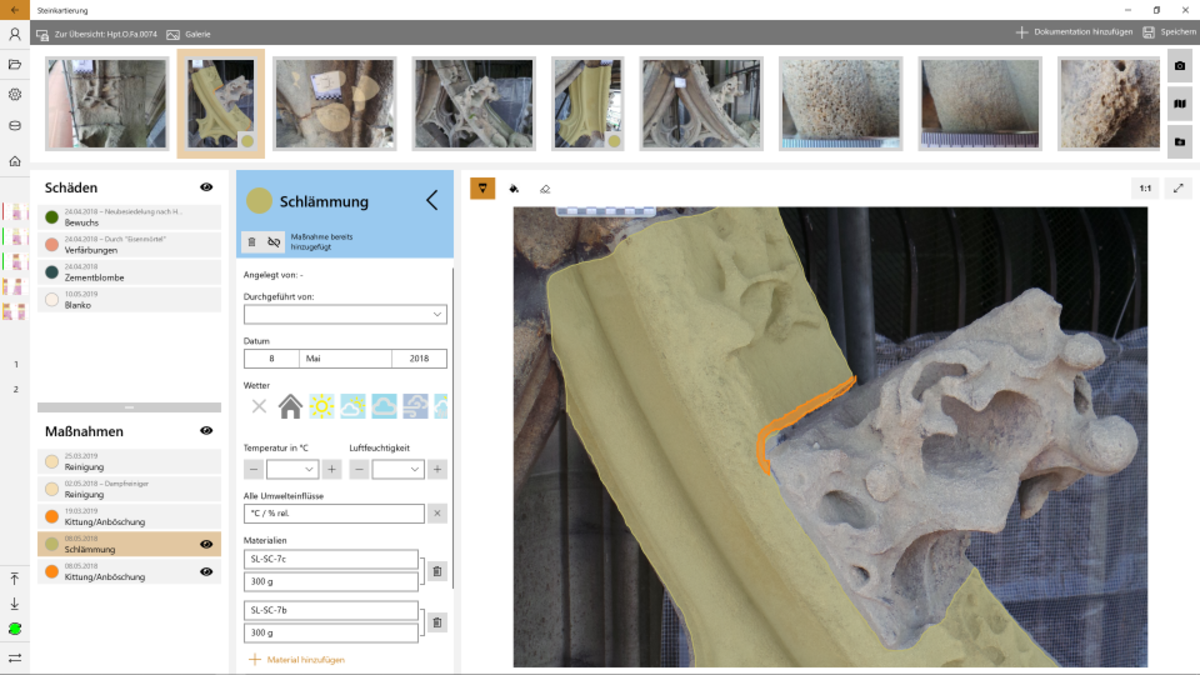
Die Restauratoren der Münsterbauhütte müssen die Schäden an den zu restaurierenden Gebäuden erfassen, um die Kosten und die Durchführung einer Restaurierung zu planen. Dabei wird Stein für Stein in Augenschein genommen und für jeden eine Menge an Daten erfasst, um den aktuellen Zustand und die notwendigen Restaurierungsarbeiten zu dokumentieren.
Um die sehr aufwendige Datenerfassung mit Fotoapparat, Papier und Bleistift zu verbessern, wurde in vergangenen Projekten eine Windows-App entwickelt, die es ermöglicht, die Daten direkt am Tablet zu erfassen. Dabei werden die Kamera des Tabletts benutzt, um Fotos zu machen, diese mit einer Stifteingabe zu markieren und zu bearbeiten. Zurück im Büro, werden die so integriert erfassten Daten direkt mit der zentralen Datenbank abgeglichen.
Nachdem im vergangenen Jahr die App "aufgeräumt" und einige Teile modernisiert wurden, steht im Sommersemester die Entwicklung von neuen Anforderungen wie z.B. Verwaltung von "ToDos", „komplexerem Rechtekonzept" usw. an. Diese müssen teilweise zunächst in Zusammenarbeit mit Mitarbeitern der Bauhütte definiert bzw. verfeinert werden.
Die App ist in C# entwickelt worden.
Ansprechpartner:
Seit einigen Jahren werden die Gremienwahlen an der Uni Ulm online über den Anbieter Polyas durchgeführt. Diese Vorgehensweise führt regelmäßig zu Diskussionen über die Sicherheit von online durchgeführten Wahlen. Grundsätzlich kann keine Onlinewahl alle Wahlgrundsätze einhalten und wurde daher schon 2009 vom Bundesverfassungsgericht für öffentliche Wahlen abgelehnt. Nichtsdestotrotz haben sich insbesondere Kryptologen damit beschäftigt, wie Wahlgrundsätze bei elektronischen Wahlen eingehalten werden können und haben dazu auch einige Ergebnisse veröffentlicht. Schließlich ist das Kernproblem der Sicherheit bei der Stimmabgabe (Stichwort: korrumpierter Rechner) noch nicht gelöst. Dennoch kann es bei Wahlen, wo die Gefahr der Manipulation aufgrund der nicht allzu großen Auswirkungen des Wahlausgangs, vorteilhaft sein, diese online bzw. elektronisch durchzuführen. Die Studierendenvertretung der Uni Ulm (StuVe) lehnte das in der Vergangenheit unter anderem aus Kostengründen und auch aus fehlender Transparenz der verwendeten Software ab.
In einem vorherigen Projekt wurden bereits viele Grundlagen geschaffen, ein für Gremienwahlen benutzbares open-source System zu erstellen. So wurden z.B. schon die kryptologischen Grundlagen und eine rudimentäre Oberfläche implementiert. In diesem Semester soll nun die Oberfläche ergänzt werden, so dass idealerweise die nächsten Gremienwahlen mit diesem Tool durchgeführt werden können. Wichtig dabe ist, dass alle möglichen Sicherheitsmechanismen (Überprüfung der eigenen Stimmabgabe, Überprüfung, ob die eigene Stimme in das Ergebnis eingeflossen ist, etc.) für die Benutzer möglichst einfach zugänglich und insbesondere mit Erklärungen auch verständlich sind.
Erste Anlaufstellen für Hintergrundwissen und Implementierungen sind

Blockchain technology enables the operation of distributed ledgers, a form of replicated database, in blockchain systems. Blockchain systems serve diverse use cases, including asset trading, seed funding, and recording of certificates, each imposing different quality requirements. Key requirements typically relate to degree of decentralization (DoD), scalability, and security. However, according to the blockchain trilemma, DoD, scalability, and security cannot be maximized simultaneously, necessitating Pareto-optimal configurations to balance trade-offs. The quality of a given system configuration can be investigated using model-based analysis. Recent research is developing various approaches to modeling and analyzing blockchain systems.
Extending an existing simulation tool, the goal of this project is to implement tool support in the form of a modeling and analysis workbench for blockchain systems. The workbench should facilitate modeling a blockchain system configuration
through a Wizard based on system parameters like:
The workbench should allow for selecting several types of analyses for the given system configuration and then trigger the execution of existing analysis algorithms to investigate the dimensions of the blockchain trilemma. While scalability and security are the focus of the simulations, DoD is optional in this project. The workbench should help answer questions like:
In addition to configuring blockchain system models and starting analyses, the workbench should provide appropriate views to visualize the analysis results. Such visualizations could take the form of histograms, cumulative distribution functions, attack trees, or attack probabilities. Building upon the analysis of single quality requirements, the tool should allow for identifying Pareto-optimal configuration candidates to answer questions like:

Attack analysis is typically conducted by cybersecurity experts, who possess in-depth knowledge in this field. However, cybersecurity experts often do their job in the development phase, or even after the software system is released. When designing the software architectures or cyber-physical systems (CPSs), architects often miss the security aspects due to their knowledge.
The attacks can propagate through the system due to a misconfiguration or an unawareness of the implicit access control policies. Selecting an appropriate mitigation technique requires a lot of expert knowledge.
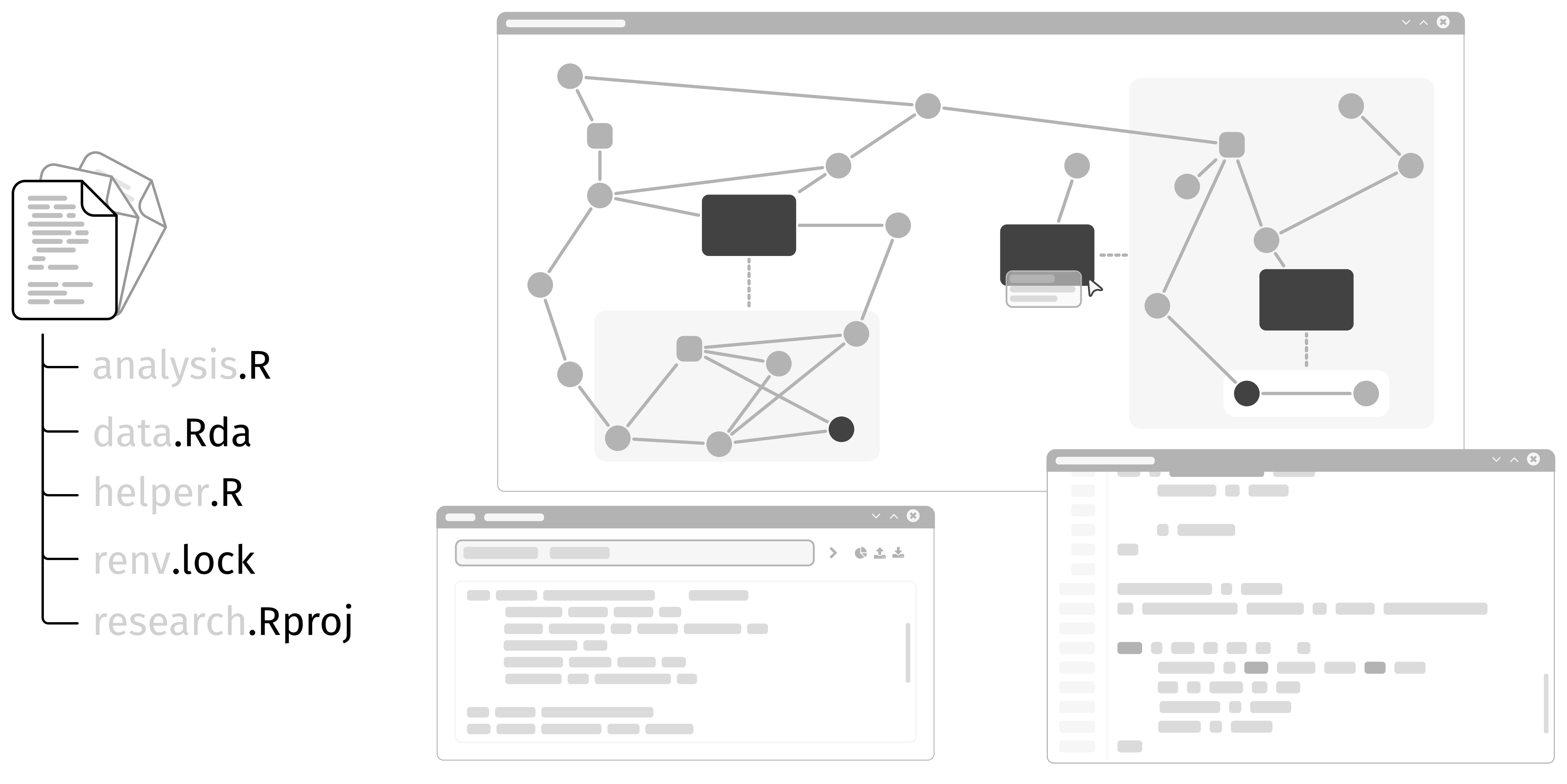
Statische Analyse bezeichnet die Untersuchung von Programmen auf Laufzeiteigenschaften ohne diese tatsächlich auszuführen. Sie ist ein integraler Bestandteil moderner Softwareentwicklung und hilft beim Identifizieren von Fehlern, Sicherheitslücken oder dem Verbessern der Lesbarkeit. Compiler verwenden statische Analyse beispielsweise, um Typfehler zu vermeiden oder möglichst optimalen Code zu generieren. Entwicklungsumgebungen oder Language Server verwenden statische Analyse, um Ihre Funktionalität wie Refactorings oder Autovervollständigung zu realisieren (Siehe dazu auch Foliensätze statische Programmanalyse).
In diesem Projekt geht es um die Arbeit an und um flowR, einem Framework für die statische Analyse von R, einer statistischen Programmiersprache die häufig in der Datenanalyse und -visualisierung eingesetzt wird. Eine ausgiebige Analyse des Daten- und Kontrollflusses ermöglicht es flowR beispielsweise ein Programm nur auf die Teile zu reduzieren, die für die Generierung einer Grafik oder die Berechnung eines statistischen Modells relevant sind (das sogenannte Program Slicing) oder mittels Abstract Interpretation die Wertebereiche von Variablen zu bestimmen.
Aktuell kann flowR als Erweiterung für Visual Studio Code, Positron und RStudio, sowie direkt als Docker Image verwendet und ausprobiert werden. Folgende Zeile ermöglicht euch beispielsweise, flowR mit seinem read-evaluate-print loop zu erkunden:
docker run -it --rm eagleoutice/flowr:latest
Wenn ihr dann im REPL zum Beispiel den Datenflussgraph eines R Ausdrucks sehen wollt, könnt ihr folgendes eingeben:
R> :df! x <- 2
Zum Verlassen, genügt ein :q flowR wird unter der GPLv3 Lizenz auf GitHub hauptsächlich in der Programmiersprache TypeScript entwickelt. Die ausführliche Dokumentation erfolgt über ein dediziertes und automatisch aktualisiertes Wiki und direkt im Code.
Dieses Semester ist das Anwendungsprojekt für flowR denkbar flexibel gestaltet und bietet eine Vielzahl an spannenden möglichen Bereichen (die sich so oder so ähnlich auch in Richtung einer Abschlussarbeit ausbauen lassen). Folgende Liste stellt einige mögliche Aufgabenbereichen vor, mit denen Ihr euch in flowR verwirklichen könnt. Die konkrete Zuteilung erfolgt dann zu Beginn des Projekts, je nach Interesse:
Interesse? Dann melde dich doch gerne bei mir und werde Teil des flowR Teams!
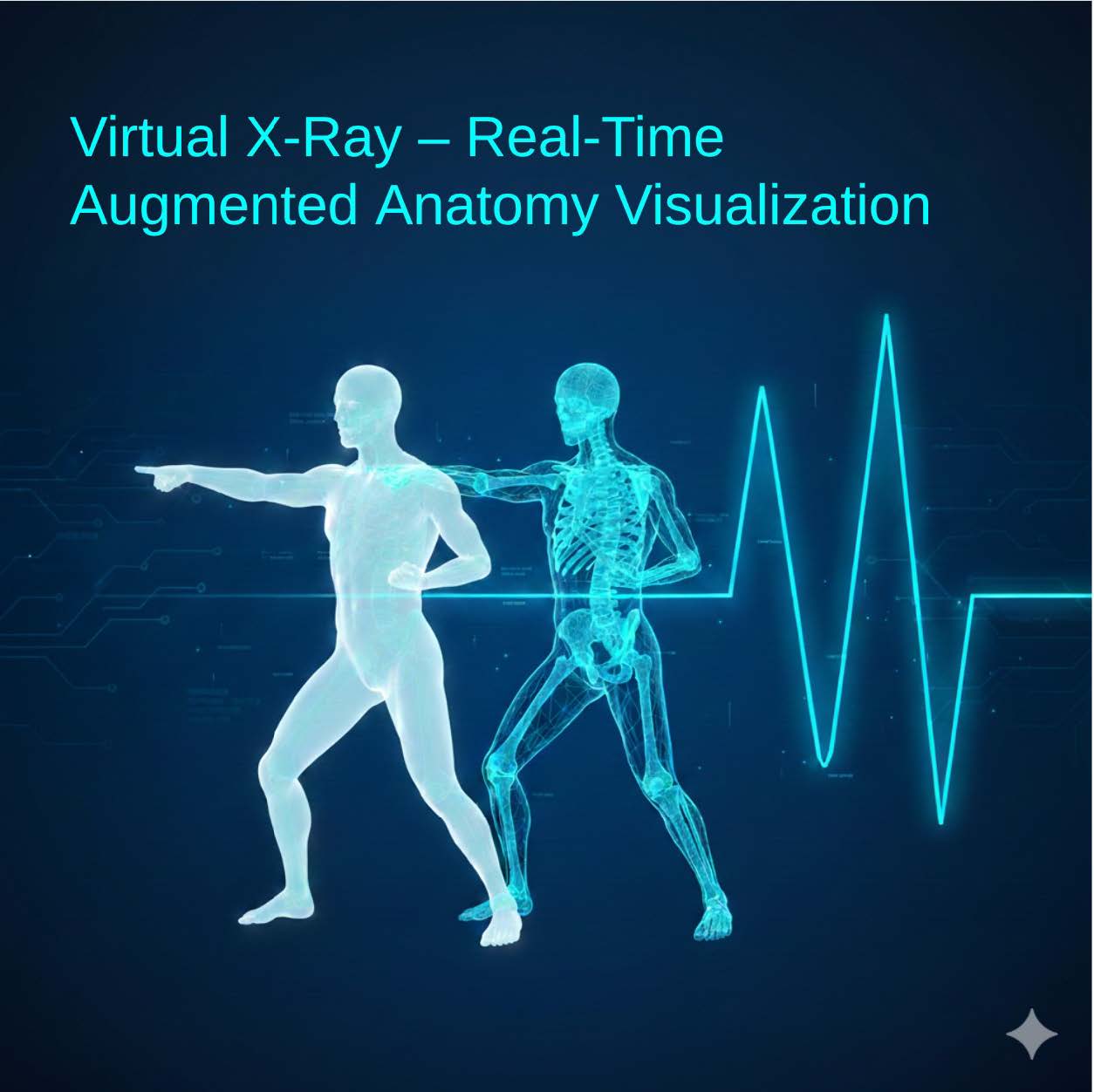
This software project aims to develop an interactive Virtual X-Ray system that visualizes internal anatomical
structures by aligning a virtual skeletal model with a real person in real time. Using live camera input, the
system detects human body landmarks and tracks movement to accurately overlay a digital skeleton that
mirrors the user’s posture and motion. The project focuses on building a real-time processing pipeline that
integrates pose estimation, skeletal modeling, motion retargeting, and visualization. The resulting system
creates the illusion of an X-ray-like view, enabling intuitive exploration of human movement and anatomy.
The application is intended for educational, demonstrational, and visualization purposes rather than
diagnosis.
The primary goal of this project is to design and implement a robust real-time system that captures human
motion from a video stream and maps it onto a virtual skeletal representation. A key challenge lies in
achieving stable and anatomically plausible alignment between detected body landmarks and the virtual
skeleton, even under continuous movement. Another objective is to explore different visualization
techniques, such as semi-transparent overlays or projected skeletal renderings, to create a convincing “see-
through” effect. The project also aims to provide interactive features that allow users to inspect joints,
observe movement dynamics, and adjust visualization parameters in real time. Ensuring smooth
performance, low latency, and modular software architecture are essential for creating a compelling and
extensible demonstration.
Unser Chatbot „BPMNGen“ soll weiterentwickelt werden. Ziel ist es, natürlichsprachliche Beschreibungen und Anforderungen automatisch in grafische BPMN 2.0-Modelle umzuwandeln – und umgekehrt (Model to Text). Dabei stehen Modellqualität, Usability und Team-Kollaboration im Fokus.
Unternehmen stehen unter der DSGVO in der Pflicht, eine Dokumentation zu führen, wenn sie personenbezogene Daten verarbeiten. GRIPL nutzt ein LLM, um DSGVO-kritische Aktivitäten direkt in einem BPMN 2.0 Modell zu erkennen. GRIPL bietet außerdem die Möglichkeit zur automatischen Erstellung und Evaluation von Datensätzen aus BPMN 2.0 Modellen.
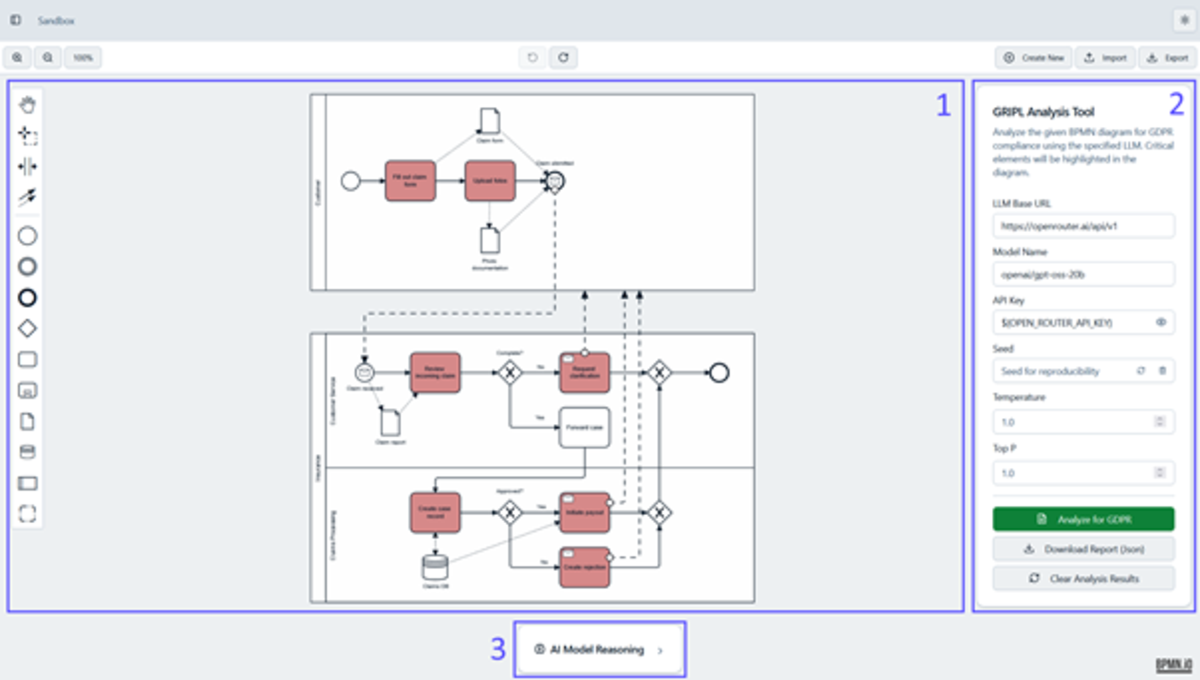
Prozessautomatisierungen erhöhen die Produktivität, indem sie wiederkehrende Aufgaben optimieren und Engpässe beseitigen. Sie senken Kosten um bis zu 30% durch geringere manuelle Eingriffe und bessere Ressourcennutzung. Zudem verbessern sie die Datenqualität und Skalierbarkeit, was fundierte Entscheidungen ermöglicht.
Im Projekt werden 3-4 LLMs mit Ollama ausgewählt und via Robocorp oder TagUI Automatisierungen erstellt. Diese sollen nach Metriken wie z.B. Accuracy, Latency, Robustness, etc. evaluiert werden. Das Ziel ist ein Vergleich von Multi-Small-Models mit Agents vs. einem einzelnen "großen" LLM mit RAG im Bereich Kosten und Reasoning.
(siehe 1. Abbildung rechts)
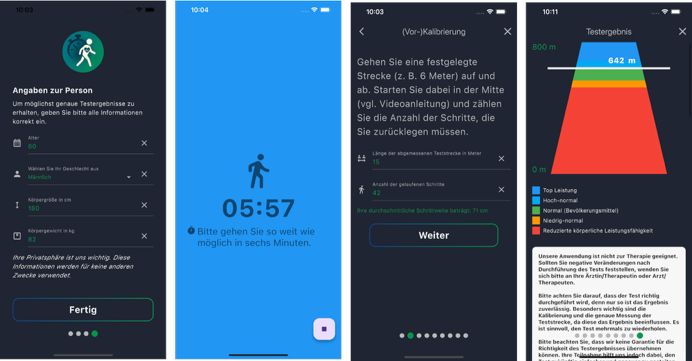
Nutzt Schrittzähler und manuelle Kalibrierung der Schrittlänge
Anmerkung: Wir hatten auch eine GPS-basierte Version, GPS funktioniert allerdings in-door nicht.

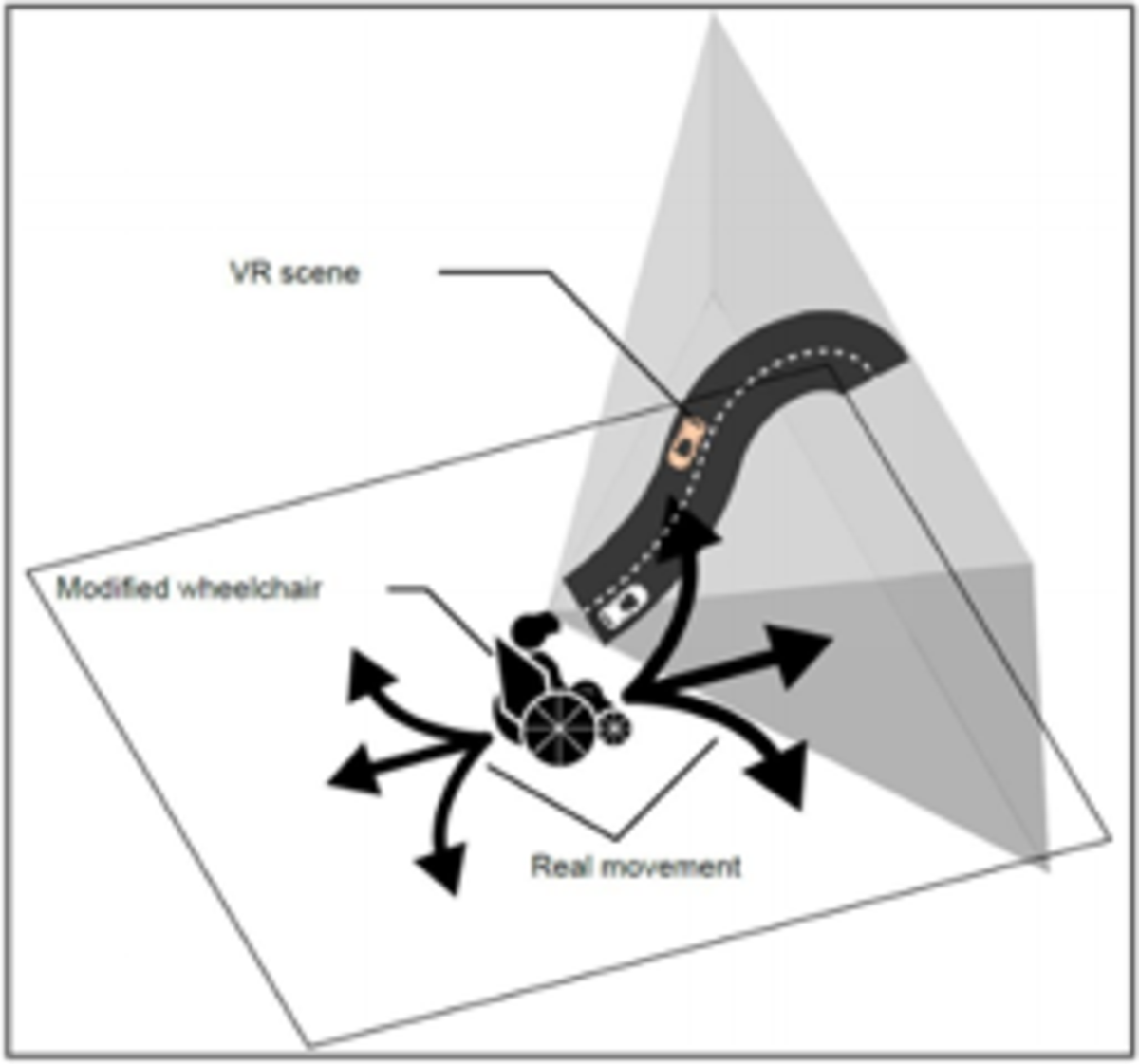
In diesem Projekt arbeitest du nicht nur an einer Simulation auf dem Bildschirm, sondern an einem echten VR-Fahrsimulator mit beweglicher Hardware. Ein motorisierter Rollstuhl in unserem Labor dient als Fahrzeugplattform und bewegt sich synchron zu einer VR-Fahrszene durch den Raum (ca. 4x4m). Während die Versuchsperson das Fahrzeug in VR erlebt, spürt sie Beschleunigungen und Kurvenkräfte. Das System wird bereits in aktuellen XR- und Mobilitätsforschungsprojekten eingesetzt und soll nun softwareseitig weiterentwickelt werden.
Ziel des Projekts ist die Entwicklung eines modernen Control-Dashboards in Unity für diesen Motion-Simulator. Eine API zwischen Unity, Arduino und den Motoren existiert bereits. Darauf aufbauend soll ein Digital-Twin-System entstehen, in dem der Rollstuhl als virtuelles Modell in Unity dargestellt und gesteuert werden kann. Dadurch lassen sich Bewegungsabläufe zuerst sicher im virtuellen Raum simulieren, bevor sie auf der echten Plattform ausgeführt werden.
Das Projekt kann hybrid durchgeführt werden:
Entwicklung und Tests am Digital Twin sind remote möglich, während praktische Experimente mit dem realen Simulator im Labor stattfinden.
Zu Beginn erhältst du ein klares Anforderungspaket für die zu entwickelnde Software, das im Verlauf gemeinsam weiterentwickelt werden kann.

Die zunehmende Komplexität von Hardware-Software-Systemen stellt unsere Gesellschaft vor eine große Herausforderung. Jeder Chip, jedes System und jede Anwendung muss entwickelt, implementiert und optimiert werden, um den steigenden Anforderungen gerecht zu werden. Dieser damit verbundene wachsende Aufwand wird oft als Design-Gap bezeichnet, da die Modellierung von Systemen und die Implementierung immer weiter auseinanderdriften.
Ein vielversprechender Ansatz, um diese Lücke zu schließen, ist die Verwendung von Model-Driven Architecture (MDA). MDA ermöglicht es, Modelle auf verschiedenen Abstraktionsebenen zu erstellen und diese dann in ausführbaren Code zu transformieren. Dieser Ansatz verspricht nicht nur eine höhere Effizienz, sondern auch eine größere Flexibilität bei der Entwicklung von komplexen Systemen. Eng verbunden mit MDA ist die formale Definition der im MDA Prozess verwendeten Modelle durch sogenannte Metamodelle und die automatische Generierung von Code – z.B. um die Erzeugung, das Lesen, das Transformieren und das Modifizieren der Modelle zu unterstützen. Meta-Modellierung und Code Generierung wird in sogenannten Meta-Modelling-Frameworks unterstützt.
Die Verwendung von MDA birgt jedoch auch Herausforderungen. Die derzeit auf dem Markt verfügbaren Meta-Modelling-Frameworks neigen dazu, sehr groß und komplex zu sein, was ihre Anwendung oft erschwert. Darüber hinaus ist der Entwurf und das Wiederverwenden von Metamodellen nicht immer trivial. Unsere jahrelange Erfahrung im Bereich MDA hat uns gezeigt, dass es hierfür spezielle Techniken und Ansätze benötigt, um die Komplexität zu reduzieren und die Effizienz zu steigern.
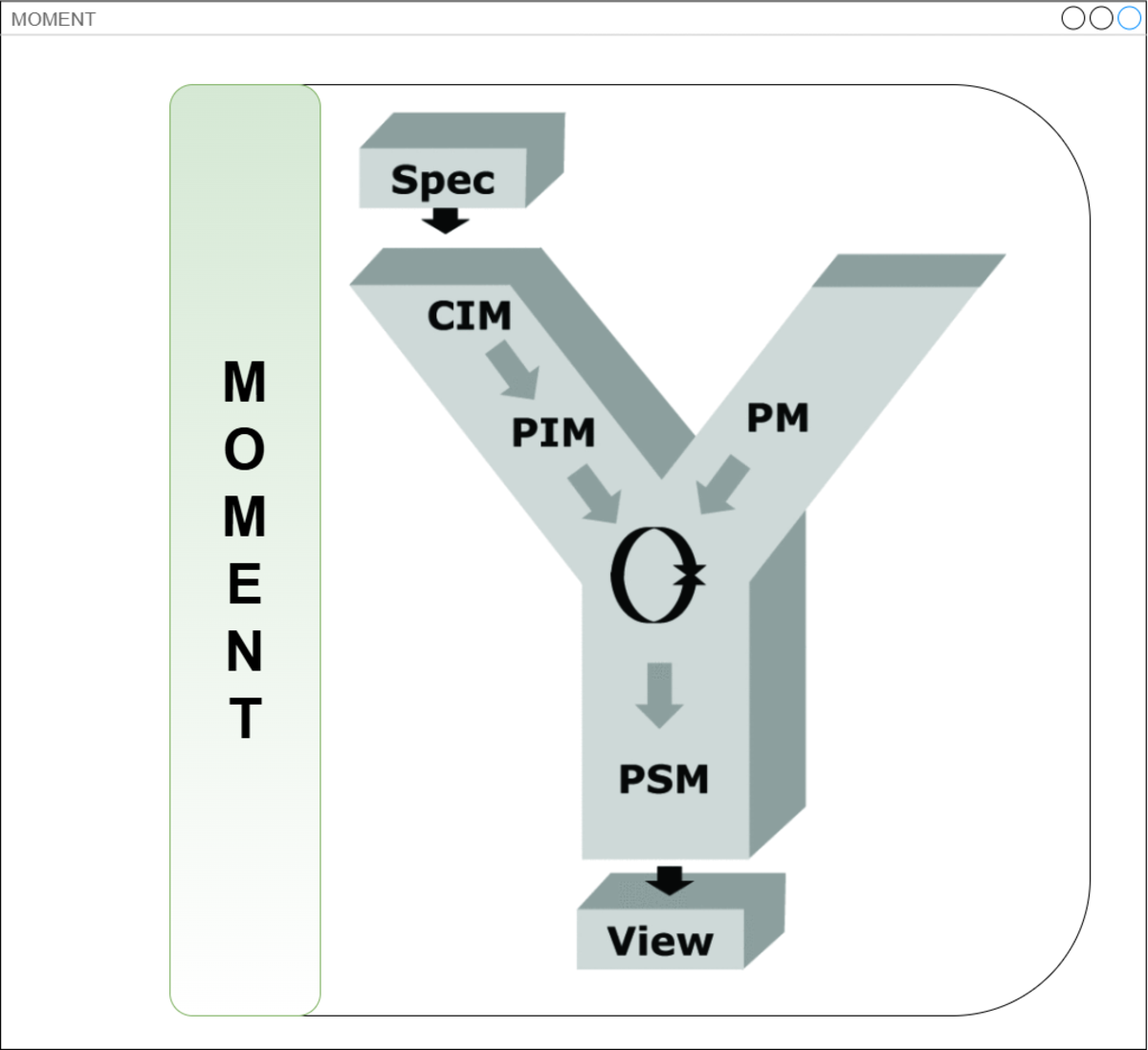
Im Rahmen dieses Projekts soll ein neues Framework MOMENT entwickelt werden, das die Vorteile von MDA mit der Notwendigkeit nach Einfachheit und Flexibilität kombiniert. MOMENT steht dabei für Meta Object Modeling and Engineering for Next-generation Technologies. Das Framework soll es ermöglichen, Modelle auf verschiedenen Abstraktionsebenen zu erstellen und diese dann in ausführbaren Code zu transformieren, ohne die Komplexität und den Aufwand zu erhöhen.
Das zu entwickelnde Framework soll eine flexible und effiziente Modellierung auf verschiedenen Abstraktionsebenen ermöglichen, ohne die Komplexität und den Aufwand zu erhöhen. Es soll möglich sein, beliebig viele Abstraktionsebenen in einer Kaskade zu schalten, um die Modellierung von komplexen Systemen zu unterstützen. Basierend auf unserer Erfahrung im Bereich MDA haben wir erkannt, dass der Entwurf und die Wiederverwendung von Metamodellen oft Herausforderungen mit sich bringen. Wir haben daher Methoden entwickelt, die wir gerne in diesem neuen System der Forschung und Lehre zur Verfügung stellen möchten, um die Modellierung und Wiederverwendung von Metamodellen zu erleichtern. Wir sind aber auch auf eure Ideen und Ansätze gespannt, welche die Welt der Metamodellierung noch weiter vereinfachen und bereichern können!
Wir formulieren Anforderungen und diskutieren Lösungsansätze. Wir bleiben technologieoffen und sind bereit, verschiedene Ansätze zu prüfen. Unsere bisherigen Prototypen und ersten Ansätze können als Ausgangspunkt dienen, aber wir möchten das Team nicht auf eine bestimmte Technologie festlegen, bevor wir nicht eine umfassende Technologiebewertung durchgeführt haben. Diese könnte neue Lösungen aufdecken, die wir bisher noch nicht in Betracht gezogen haben.
Im Rahmen des Projekts erhalten Studierende die Möglichkeit, praxisnahe Einblicke in die industrielle Softwareentwicklung zu gewinnen. Ziel ist es, unter realitätsnahen Bedingungen gemeinsam im Team Software zu konzipieren, zu entwickeln und zu testen – ganz im Sinne moderner, kollaborativer Entwicklungsprozesse in der Industrie.
Das Projekt „Build Your Own SaaS Startup“ richtet sich hierbei an Studierende, die unternehmerisches Denken mit technischer Umsetzung verbinden möchten. In diesem Projekt entwickeln die Teilnehmenden eigenständig ein Software-as-a-Service (SaaS)-Produkt, das auf einer mitgelieferten technischen Anforderungsliste basiert. Es stehen hierbei nicht nur die funktionalen Anforderungen im Fokus, sondern auch die Gestaltung eines professionellen Entwicklungsprozesses.
Zu den zentralen Aspekten gehören:
Ziel ist es, ein marktfähiges Produkt zu entwickeln – von der Idee bis zum Deployment – und dabei wertvolle Erfahrungen in der Softwareentwicklung, im Projektmanagement und im Aufbau eines digitalen Produkts zu sammeln.
Beispielhafte Produktideen:
Im Rahmen des Projekts wird erwartet, dass das Team ein SaaS-Produkt entwickelt, das die folgenden technischen Anforderungen erfüllt:
immersight entwickelt mit dem 3D-Workroom ein System, um Räume mittels 360°-Kamera zu erfassen, zu vermessen und virtuell zu betreten. Für diese Anwendung existiert keine native App - sondern eine Web-Anwendung basierend auf JavaScript, konkret ThreeJS. Dabei gibt es einen Edit-Mode (um Messungen vorzunehmen und 3D-Modelle zu platzieren, geht nur logged in) und einen Viewing-Mode, wenn man einen Virtuellen Raum einfach nur per Link teilt (anonym).
Hier ein Biespiel (Viewing-Mode): https://3d-showroom.com/projectlink/QyMVuVjQsO8jk3f148zs
Die Projekte im 3D-Workroom dienen meistens der Baustellendokumentation und -kommunikation. Das bedeutet, verschiedene Mitarbeiter eines Bauunternehmens machen zu verschiedenen Zeitpunkten mit der 360°-Kamera Aufnahmen vom Baufortschritt und laden diese Aufnahmen dann ins Projekt. Eine Vermessung und Begehung ist derzeit nur am PC, Laptop oder Tablet per Webbrowser möglich. Um einen noch immersiveren Zugang zu den virtuellen Räumen zu erhalten, soll es ermöglicht werden, diese Räume mittels XR-Brille zu betreten und ggf. mit dem Raum zu interagieren. Das heißt, den Raum auszumessen und Objekte einzusetzen.
Es soll der aktuelle JS-Code, der den virtuellen Raum lädt und darstellt, erweitert oder umgeschrieben werden auf WebXR (mittels ThreeJS), sodass man die Räume immersiv mit einer VR-Brille (Meta Quest oder GoogleXR) betrachten kann. Die WebXR Anwendung kann durch Aufrufen des Links zum Virtuellen Raum mittels XR-Device gestartet werden (Standalone-Mode). Genau so könnte aber der Virtuelle Raum auf einem PC/Laptop/Tablet geöffnet werden, dann über einen QR-Code ein XR-Client direkt auf dem XR-Device gestartet werden. Die Web-Anwendung auf dem Browser im PC/Laptop/Tablet könnte mittels Web-Schnittstelle mit dem XR-Device kommunizieren und Informationen (z.B. aktuelle Blickrichtung) zurücksenden (Client-Mode).
Der aktuelle JS-Code zum virtuellen Begehen hat einen Edit-Mode (User ist logged in) und so kann der Benutzer aktiv im Raum Veränderungen vornehmen. Das bedeutet, er kann Messungen im Raum machen oder auch 3D-Modelle platzieren. Diese Interaktion ist auch mittels XR-Brille möglich, da die meisten Brillen noch Controller für die Hände mitbringen. Es soll überprüft werden, in welchem Umfang Interaktionen im XR-Mode mit XR-Brille möglich sind.
Mit der 3D-Showroom Windows Software hat die Firma immersight noch einen Standalone Client für die Präsentation von Virtuellen Räumen, die häufig an einem PC+TV verwendet wird. Diese wird im Verkaufsprozess mit neuen Kunden verwendet. Hier ist ein Beispiel für einen virtuellen Raum: https://3d-showroom.com/kojelink/pp7xhH
Es ist möglich, eine Google Cardboard VR-Brille zu verwenden. Für Android wurde eine eigene App für diesen Zweck entwickelt (Panoramabrille-App). Diese App ist veraltet und die Funktion könnte durch den neuen WebXR-Client auch übernommen werden.