Projektvorstellung
Die Projektvorstellung der Projekte im WiSe 24/25 fand am Mittwoch, 17.07.2024 statt.
Über folgenden Link können Sie die Aufzeichnung ansehen:
Auf dieser Seite werden ab dem 15. Juli 2024 kurz die im WiSe 2024/25 angebotenen Projekte beschrieben. Es wird dabei nicht zwischen Bachelor und Masterprojekten unterschieden, da wir gemischte Gruppen zu lassen.
Wenn Sie im nächsten Semester eines der unten stehenden Projekte belegen möchten, senden Sie bitte bis zum 07.08.24 eine E-Mail mit priorisierten Wünschen (3-5 Projekte) an Alexander Raschke.
Bitte auch die Buchstaben zur eindeutigen Kennzeichnung in der Mail mit angeben!
Bei Fragen zu den Projekten wenden Sie sich bitte ebenfalls an Alexander Raschke.
Weitere Informationen für den Studiengang Software Engineering
Eine Galerie der bisherigen Projekte finden Sie hier: Bisherige SE-Projekte
Die Projektvorstellung der Projekte im WiSe 24/25 fand am Mittwoch, 17.07.2024 statt.
Über folgenden Link können Sie die Aufzeichnung ansehen:
A: Unterstützung der Münsterbauhütte bei Kartierungsarbeiten
B: snowballR
C: Automated Architecture Analysis Kontext
D: Waddle: Spielerisch Programmieren Lernen
E: WebAR Lego Konfigurator
F: Family Kanban
G: Tool zur Verwaltung und Analyse von Exchange Days
H: Automatische Arbeitsplatzbuchung
I: Automated Model Generation for Self-Adaptive Microservices
J: Craftara Hub - Digitalisierung im Handwerk
K: Weiterentwicklung und Optimierung eines Chatbots im Bereich der Prozessmodellierung
L: KeepMeAlive3D - Visualisierung langlebiger, komplexer Produktionsmaschinen
M: Kamera-basiertes Eye-Tracking
N: Manufacturing Domain Specific Internationalization
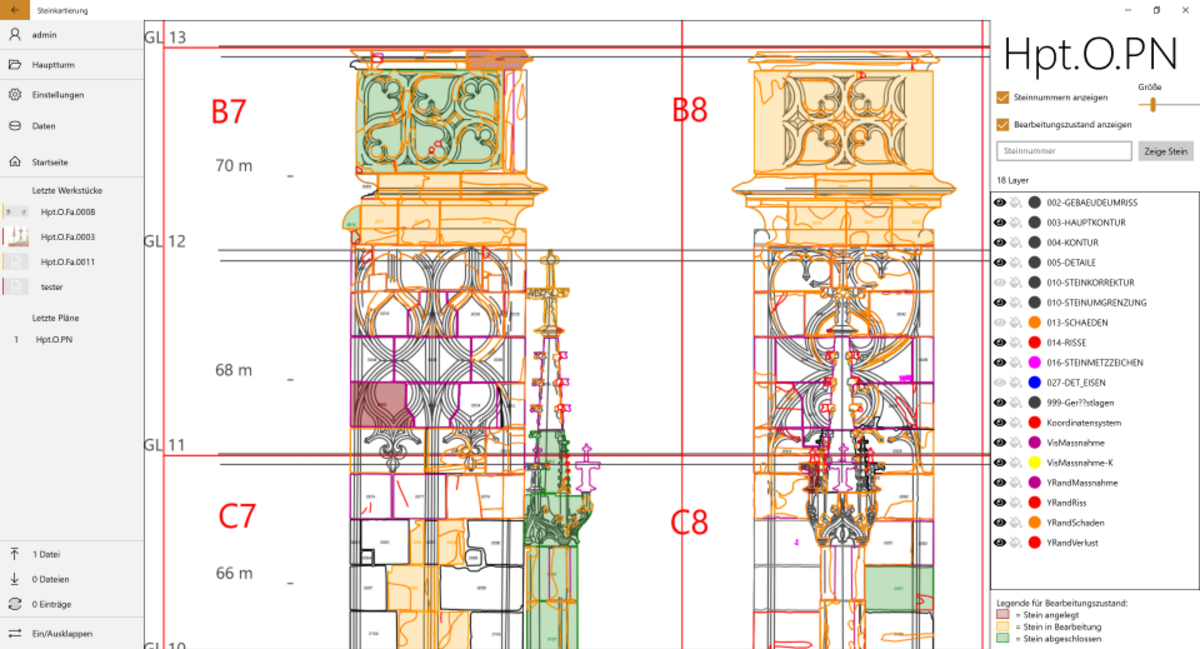
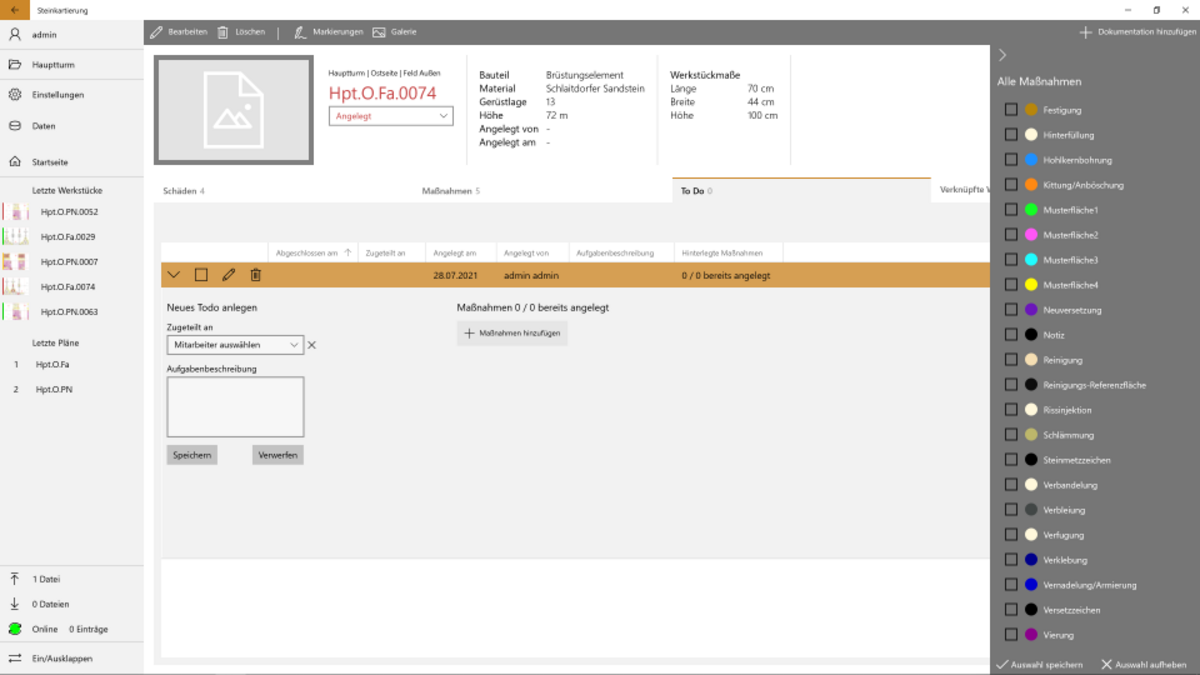
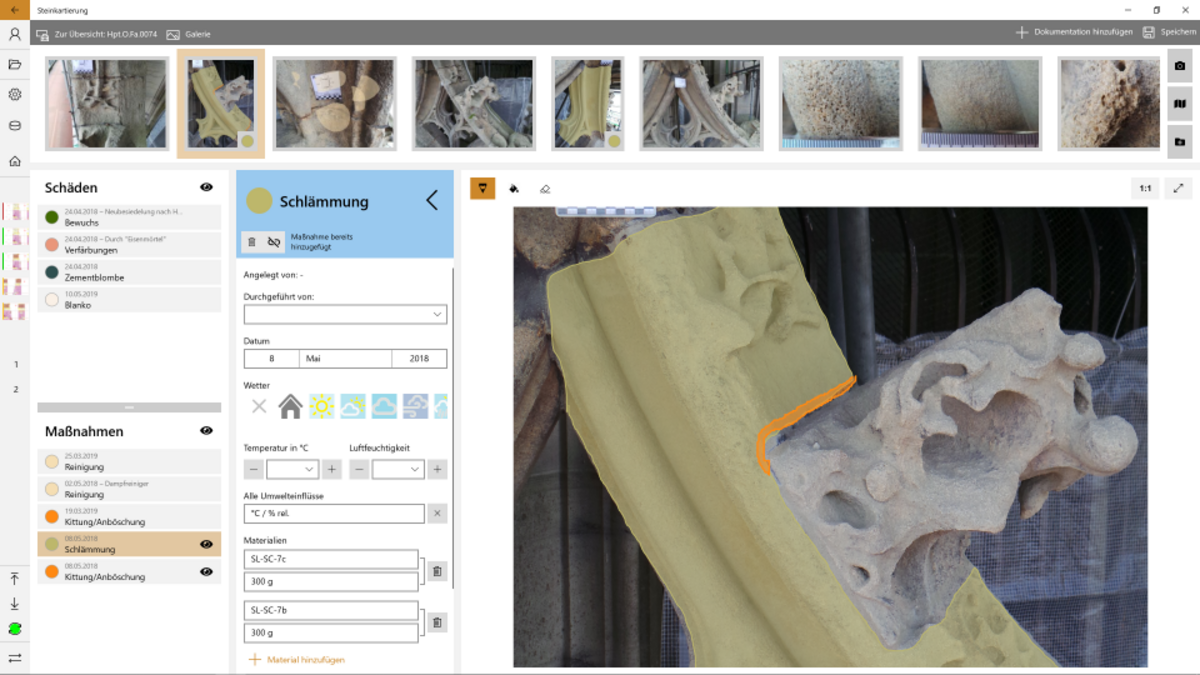
Die Restauratoren der Münsterbauhütte müssen die Schäden an den zu restaurienden Gebäuden erfassen, um die Kosten und die Durchführung einer Restaurierung zu planen. Dabei wird Stein für Stein in Augenschein genommen und für jeden eine Menge an Daten erfasst, um den aktuellen Zustand und die notwendigen Restaurierungsarbeiten zu dokumentieren.
Um die sehr aufwändige Datenerfassung mit Fotoapparat, Papier und Bleistift zu verbessern, wurde in vergangenen Projekten eine Windows-App entwickelt, die es ermöglicht, die Daten direkt am Tablett zu erfassen. Dabei werden die Kamera des Tabletts benutzt, um Fotos zu machen, diese mit einer Stifteingabe zu markieren und zu bearbeiten. Zurück im Büro, werden die so integriert erfassten Daten direkt mit der zentralen Datenbank abgeglichen.
Nachdem im vergangenen Jahr die App "aufgeräumt" wurde und einige Teile modernisiert wurden, steht im Wintersemester die Entwicklung von neuen Anforderungen wie z.B. Verwaltung von "ToDos", "komplexeres Rechtekonzepte" usw. an. Diese müssen teilweise zunächst in Zusammenarbeit mit Mitarbeitern der Bauhütte definiert bzw. verfeinert werden.
Die App ist in C# entwickelt worden.
Ansprechpartner:
In der Wissenschaft ist es üblich, zu Beginn eines neuen Projekts, einer Abschlussarbeit oder einer Publikation mit einer umfangreichen Literatur-Recherche zu beginnen, um einen Überblick über das Forschungsfeld und verwandte Arbeiten zu erhalten. Diese Recherche kann entweder unsystematisch oder systematisch erfolgen. Der systematische Ansatz wird allgemein als Systematic Literature Review, kurz SLR, bezeichnet. Dabei gibt es verschiedene Methoden, wie beispielsweise Systematic Database Query oder Snowballing, welche auch oft kombiniert werden. Im Falle des Snowballings werden, von einem initialen Startset von Papern ausgehend, in mehreren Iterationen zitierte als auch referenzierende Paper erfasst. Die gefundenen Paper werden hinsichtlich ihrer behandelten Themen bewertet, ob sie in der Menge bleiben oder nicht.
Bisher ist dieser Prozess mit sehr viel Handarbeit verbunden, da alle notwendigen Daten per Hand zusammengetragen werden müssen. Im Rahmen dieses Projekts soll daher eine frei zugängliche Anwendung entstehen, welche Forscherinnen und Forscher (aber auch Studierende) dabei unterstützt, kollaborativ eine SLR mittels Snowballing durchzuführen. Es sollen verschiedene frei zugängliche Literatur-Datenbanken, wie CrossRef, OCI oder SemanticScholar, abgefragt und die erhaltenen Daten zusammengeführt werden. Auch die manuelle Eingabe von Papern bzw. deren Meta-Daten soll möglich sein. Abschließend sollen alle beteiligten Personen die Möglichkeit haben, die erfassten Paper zu bewerten und/oder zu diskutieren.
In einem früheren Projekt wurde eine erster Prototyp dazu entwickelt, dessen Frontend in diesem Semester deutlich verbessert (bzw. ggf. neu entwickelt) werden soll. Auch im Backend sind einige Verbesserungen wie z.B. KI Unterstützung denkbar.

Moderne Autos müssen inzwischen viele IT-Sicherheitsrichtlinien erfüllen. Dazu gehört, das Auto auf Cybersicherheit zu prüfen und zu (Pen-)Testen. Ein Teiler dieser Prüfung ist eine Architekturanalyse. Dabei wird die Netzwerktopologie des Autos betrachtet und mögliche Angriffspfade von Eintrittspunkten (wie WiFi, BT, …) zu möglichen Zielen (sog. Critical Elements) ermittelt. Es kommen noch weitere Aspekte, wie eine TARA, Systemanalyse, etc.. dazu, aber diese sind für das Projekt nicht relevant. Mit Hilfe der Architekturanalyse wird dann mit den Security Architekten ein Scope für den Pentest festgelegt; und unsere Pentester versuchen dann über die ermittelten Angriffspfade das Auto zu hacken. Wir, ein Team bei Mercedes-Benz Tech Innovation (MBTI), übernehmen diese Aufgabe von der Mercedes-Benz AG. Weitere Details und z.B. eine Führung durch unsere Hackingwerkstatt gibt es dann für die interessierte Gruppe.
Momentan wird händisch aus einem PDF-Diagramm, ein Netzwerkdiagramm in Visio gezeichnet, eingefärbt und ein kleine Python Script übernimmt eine simple Angriffspfadanalyse.


Waddle ist ein Programmierlernspiel (ähnlich zu Scratch), bei dem Schüler:innen ab der 6. Klasse, Stück für Stück an die Grundkonzepte des Programmierens herangeführt werden. Sie durchlaufen dabei immer schwierigere Level, bei denen Sie mithilfe von selbstgeschriebenen Programmen (in einer eigenen DSL, Aufgaben erfüllen müssen. Besonders ist hierbei, dass alle interaktiven Elemente ebenfalls in der selben DSL vorgegeben sind, sodass die Schüler:innen gezielt existierenden Code lesen und verstehen müssen, um die Aufgaben zu meistern.
Waddle kann unter https://sp2.informatik.uni-ulm.de/waddle ausprobiert werden.
Waddle besitzt aktuell:
Waddle ist in TypeScript implementiert.
Im Anwendungsprojekt ist das Ziel, ganz allgemein, Waddle um diverse Features zu erweitern, wobei die konkrete Auswahl und Ausprägung in einem ersten Treffen zu Beginn des Projektes gemeinsam festgelegt wird:

Die immersight GmbH entwickelt mit dem 3D-Showroom eine Cloud-Lösung für Virtuelle Ausstellung und mit dem 3D-Workroom zur Baustellendokumentation und -kommunikation. Die Kunden sind Handwerker oder Bauunternehmen, welche Räume sanieren und Material und Produkte verbauen.
Ein spannendes Feld sind Produktkonfiguratoren, welche es dem Endkunden ermöglichen, das gewünschte Produkt in seinen speziellen Ausprägungen zu konfigurieren. Ein weiteres spannendes Feld sind digitale Bauanleitungen, welche es dem Endkunden und/oder dem Monteur ermöglichen, das Produkt aus Einzelteilen einfach aufzubauen.
In diesem Projekt soll ein Lego-Klo aus ca. 20 Teilen als Übungsobjekt dienen, um sich den beiden spannenden Feldern zu nähern. Einerseits handelt es sich um ein Produkt, welches aus Einzelteilen zusammengebaut wird, andererseits könnte man aus den Einzelteilen auch ein anderes Produkt bauen (konfigurieren). In diesem Projekt wird sich auf eine Bauvariante (eine Konfiguration beschränkt), jedoch sollen die Einzelteile als 3D-Modell so angelegt sein, dass man auch jederzeit eine weitere Konfiguration erstellen könnte.
Der Fokus liegt auf dem Zusammenbauen der einen Konfiguration aus ca. 20 Teilen. Der Nutzer soll mittels AR-Technologie unterstützt werden. Die Anwendung soll eine Web-AR Anwendung sein, sodass man sie einfach per QR-Code / Link aufrufen kann. Bevorzugt soll ThreeJS genutzt werden. Eine Nutzung mittels AR-Brille ist nicht direkt vorgesehen, darf aber auch funktionieren (insofern die AR-Brille WebAR unterstützt).
In der aller einfachsten Lösung wird eine Web-AR-Anwendung gebaut (bevorzugt mit ThreeJS) welche das fertig zusammengebaute Lego-Klo erkennt und dem Nutzer Feedback gibt (Lego-Klo erkannt, korrekt zusammengebaut, Merkmale des Klos als AR-Textfield).
Für eine gute Lösung wird eine Web-AR-Anwendung gebaut (bevorzugt mit ThreeJS) welche eine interaktive Anleitung bietet, wie man das Lego-Klo aus ca. 20 Teilen Schritt für Schritt zusammenbaut. Nach dem Zusammenbauen kann die Anwendung das Lego-Klo erkennen und dem Nutzer Feedback geben (Lego-Klo erkannt, korrekt zusammengebaut, Merkmale des Klos als AR-Textfield).
In einer erweiterten Lösung wird eine Web-AR-Anwendung gebaut (bevorzugt mit ThreeJS), welches den aktuellen Bauzustand erkennt (z.B. nach 12 korrekt verbauten Teilen) und dem Nutzer auf dem (nicht fertig gebauten Klo) visualisiert, welches Teil als nächstes verbaut wird. Nach dem Zusammenbauen kann die Anwendung das Lego-Klo erkennen und dem Nutzer Feedback geben (Lego-Klo erkannt, korrekt zusammengebaut, Merkmale des Klos als AR-Textfield).
In einer übertrieben guten Lösung wird eine Web-AR-Anwendung gebaut (bevorzugt mit ThreeJS), welche die ca. 20 Einzelteile auf dem Tisch liegend erkennt und identifiziert und dem Nutzer eine interaktive Anleitung bietet, welches Teil er als nächstes wie verbauen muss. Das gesuchte Einzelteil wird mit AR-Visualisierung markiert und dem Nutzer so gezeigt, welches Einzelteil er als nächstes verbauen soll. Desweiteren wird beim Betrachten des aktuellen Bauzustandes durch die Anwendung erkannt, in welcher Bauphase sich das Klo befindet und es wird das nächste Teil auf den aktuellen Bauzustand mittels AR projiziert. Nach dem Zusammenbauen kann die Anwendung das Lego-Klo erkennen und dem Nutzer Feedback geben (Lego-Klo erkannt, korrekt zusammengebaut, Merkmale des Klos als AR-Textfield).

In Familien mit Kindern fallen Aufgaben an, die mit Älterwerden der Kinder immer mehr unter allen Familienmitgliedern verteilt werden. Im Rahmen dieses Projekts soll diese familieninterne Aufgabenkoordination mit einem, im Rahmen des Projekts zu entwickelnden Werkzeug unterstützt werden. Das Werkzeug soll sich einige Konzepte aus KANBAN zu Nutze machen und die Transparenz bzgl. der Familienaufgaben erhöhen. Darüber hinaus soll das Werkzeug Anreize schaffen, sich an den Familienaufgaben zu beteiligen.
Adesso bietet den Kindern seiner Mitarbeiter:innen bereits heute das Portal „adessini“ (https://www.adessini.de) an, über welches die angemeldeten Kinder kleine Aufgaben erfüllen, Spiele spielen und zu besonderen Anlässen kleine Aufmerksamkeiten bekommen können. „adessini“ soll durch das Nachfolgeprojekt „Cosmic Coders“ (App) abgelöst werden. Die im Rahmen dieses Projekts entwickelte Lösung „Family- Kanban“ soll sich möglichst in die Cosmic Coders App integrieren lassen.
Bei der itestra GmbH spielt der Wissensaustausch eine große Rolle. Jeden Monat werden Exchange Days veranstaltet, bei denen verschiedene Workshops und Trainings (z.B.: SQL Workshop, Requirements Engineering Training etc.) angeboten werden. Um die Qualität dieser Events zu sichern und kontinuierlich zu verbessern, ist das Einholen von Feedback von den Teilnehmenden entscheidend. Bisher erfolgt die Feedback-Erfassung manuell und dezentral, was zu einer unübersichtlichen Datensammlung und ineffizienten Auswertung führt.
Das Tool soll dazu beitragen, die Exchange Days effizienter zu organisieren, die Teilnehmerzufriedenheit zu steigern und die Qualität der Veranstaltungen kontinuierlich zu verbessern.
Die Technologien können frei gewählt werden, optional kann es als Odoo-Plugin umgesetzt werden.

Die Firma eXXcellent solutions GmbH hat vor längerer Zeit shared desks eingeführt. Die Mitarbeitenden buchen sich hierfür manuell einen Platz über Desk.ly. Jedoch wird dieser manuelle Check-In Prozess längst nicht von allen Mitarbeitenden genutzt. Um einen echten Nutzen aus shared desks zu ziehen, ist es jedoch erforderlich, dass alle Mitarbeitenden, die an einem bestimmten Tag im Büro sind, in Desk.ly eingetragen sind. Beispielsweise kann so sichergestellt werden, dass niemand alleine im Büro sitzen muss.
Ziel dieses Projekts ist ein automatischer Check-In Prozess aller Mitarbeitenden mittels automatischer Personenerkennung. Hierfür könnten Kameras an der Eingangstür sowie in den einzelnen Büros installiert werden. Die Anwendung könnte dieses Videomaterial in Echtzeit auswerten, die Gesichter ankommender Mitarbeitender erkennen und diese der jeweils passenden Person zuordnen. Anschließend könnte es verschiedene mögliche Schritte geben, die die Anwendung als nächstes vornimmt:

Self-Adaptive systems are designed to autonomously adjust their behavior and configurations in response to environmental and operational changes, ensuring continued effectiveness, reliability, and efficiency. MENTOR aims to enhance the explainability of these self-adaptive processes within the cloud-native domain. To further evaluate and improve MENTOR, we now seek to develop models of self-adaptive micro systems.
In this new project, the focus will be on the automatic generation of models for these self-adaptive micro systems using Palladio, a software architecture simulation approach. The goal is to create a tool that can generate these models based on user-defined constraints. Users will be able to specify parameters such as the number of components, the number of scaling policies, and other relevant constraints. The system will then automatically generate a suitable model that adheres to these specifications.
The technology used for the implementation is flexible, allowing the choice of any suitable language and technology aside from Palladio. The approach for model generation is also open-ended, with recommendations including constraint solving, the use of large language models (LLMs), or a combination of both.
Digitalisierung ist in Deutschland lange noch nicht in allen Bereichen angekommen. Vor allem im Handwerk mangelt es an Digitalisierung. Auftragserstellung und Verwaltung könnte durch Digitalisierung effizienter und teils automatisiert gestaltet werden. Darüber hinaus sind vor allem manuelle Arbeiten wie das Aufmaß einer Fassade sehr fehleranfällig, da verschiedene Methoden verwendet werden. Obwohl es bereits einige ERP Systeme für Handwerker gibt, fehlt es an verlässlichen Gesamtlösungen, die vom Vermessen über die Auftragserstellung bis zur Auftragsverwaltung alle Schritte abdecken.
Das Hauptziel des Projekts ist es, eine mobile App für iOS und Android zu entwickeln, die Fassaden vermessen kann. Dazu sollen Möglichkeiten zur präzisen Vermessung von großen Gegenständen wie Fassaden, zB mittels KI Algorithmen, untersucht werden. Je nach Teamgröße wird das System mit einem Web Dashboard zur Auftragsverwaltung erweitert.

Im Rahmen des Projekts soll ein Chatbot weiterentwickelt werden, der natürlichsprachige Prozessbeschreibungen in grafische Modelle transformieren kann. Dies erfolgt auf Basis eines Large Language Models (LLM). Ziel ist es, die Transformationen zu optimieren und Aspekte wie Pools, Lanes und Ereignisse korrekt abzubilden. Desweiteren soll auch die umgekehrte Richtung - Model to Text - ergänzt werden. Ein besonderer Fokus liegt auf der Optimierung des Layouts der generierten grafischen Modelle, um eine klare und verständliche Darstellung sicherzustellen.
Im Verlauf des Projekts werden die Studierenden Kenntnisse in der Anwendung und Feintuning von LLMs sowie in der Nutzung von Open Source Tools zur grafischen Prozessmodellierung erwerben. Sie entwickeln innovative Ansätze zur bidirektionalen Transformation zwischen Text und grafischen Modellen und sammeln praktische Erfahrung in der Entwicklung komplexer Software-Anwendungen.
Abhängig von der Teilnehmendenzahl entwickeln wir ggf. auch noch eine App-Version des Chatbots.

Heutige Produktionsmaschinen bestehen aus mehreren tausend Komponenten und Sub-Komponenten. Anders als viele Konsumgeräte werden diese Maschinen oftmals Jahrzehnte lang eingesetzt, gewartet und verbessert. Oft werden Wartungsbücher auf Papier oder in vielen verteilten Einzelsystemen geführt. Mitarbeiter, die nicht mit der spezifischen Maschine vertraut sind, müssen oft mehrere Stellen anfragen und Informationsfragmente zusammensetzen. Diese Informationen sind allerdings von hoher Bedeutung, wenn es darum geht, ob eine Maschine weiterbetrieben, umgebaut oder vollständig ersetzt wird. Darüber hinaus werden historische Daten einzelner Komponenten (z. B. Event Logs) genutzt, um deren Performance rasch einschätzen und Abweichungen oder Probleme früher erkennen zu können.
Ziel des SE-Projekts ist es, die technische Grundlage für das o.g. System zu liefern. Hierbei kann entweder die 3D-Darstellung oder die Versionierung der Daten für die einzelnen Wartungsschritte priorisiert werden. Konkret soll es mittels 3D-Engine möglich gemacht werden, CAD-Dateien grafisch anzuzeigen sowie Bereiche im CAD-Modell anzuzeigen, die zu einer Komponente gehören. Ebenso sollen Wartungsinformationen für jede Komponente angezeigt werden. Um diese Wartungsinformationen nutzbar zu machen, benötigt das System eine Möglichkeit, diese kollaborativ zu versionieren und zugänglich zu machen. Je nach Größe des Teams sind hier weitere Features wie das Einbinden von Echtzeitdaten aus IoT Geräten möglich.

Eye Tracking ermöglicht die Erfassung der visuellen Aufmerksamkeit von Benutzern und wird im Bereich der Mensch-Computer-Interaktion (MCI) sowohl als methodisches Werkzeug zur Evaluation von Benutzerschnittstellen als auch zur augenbasierten Interaktion eingesetzt [1]. Allerdings ist die derzeit verfügbare Hard- und Software für Eye-Tracking kostenintensiv und nicht allgemein verfügbar, was eine breite Anwendung erheblich einschränkt. Obwohl Kamera-basiertes Eye-Tracking dank der Fortschritte im Bereich der Computer Vision bereits möglich ist [2, 3], fehlt es an einer einfach zu bedienenden, vielseitig einsetzbaren, leicht zu integrierenden und offenen Lösung hierfür.
Dieses Projekt zielt darauf ab, eine kostengünstige und einfache Kamera-basierte Eye-Tracking-Lösung bereitzustellen, die insbesondere im Bereich der MCI-Forschung für augenbasierte Interaktion und Datenerfassung einsetzbar ist und leicht in bestehende Systeme integriert werden kann.
In einem früheren SE-Projekt wurde bereits erfolgreich ein Unity-Plugin implementiert, das Eye-Tracking auf Desktop- und Laptop-Computern ermöglicht. Ziel des aktuellen Projekts ist die Weiterentwicklung dieses Plugins. Dies beinhaltet die Optimierung der Benutzererfahrung, insbesondere im Bereich der Kalibrierung und Validierung des Eye Trackers. Darüber hinaus soll die ML-basierte Estimation Pipeline durch das modulare Hinzufügen weiterer Blickdatensätze, Estimations- und Face Recognition-Modelle verbessert werden. Weitere mögliche Ziele sind die Erweiterung der API um Funktionen für Entwicklende und Forschende sowie die Portierung des Plugins auf Android-Geräte, um Eye-Tracking auf Smartphones zu ermöglichen. Die Ziele werden im Rahmen der Projektplanung gemeinsam mit der Projektgruppe festgelegt.
[1] Päivi Majaranta and Andreas Bulling. 2014. Eye Tracking and Eye-Based Human–Computer Interaction. In Advances in Physiological Computing, Stephen H. Fairclough and Kiel Gilleade (eds.). Springer, London, 39–65. https://doi.org/10.1007/978-1-4471-6392-3_3
[2] Kyle Krafka, Aditya Khosla, Petr Kellnhofer, Harini Kannan, Suchendra Bhandarkar, Wojciech Matusik, and Antonio Torralba. 2016. Eye Tracking for Everyone. 2016. 2176–2184. . Retrieved July 14, 2023 from https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Krafka_Eye_Tracking_for_CVPR_2016_paper.html
[3] Xucong Zhang, Yusuke Sugano, and Andreas Bulling. 2019. Evaluation of Appearance-Based Methods and Implications for Gaze-Based Applications. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19), May 02, 2019, New York, NY, USA. Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/3290605.3300646
Manufacturing Execution Systems (MES) are software solutions used to manage and monitor the production process in a manufacturing environment. They help to track and optimize the production process by providing real-time data on the status of machines, inventory levels, and workforce productivity.
MES are used in a variety of industries including automotive, aerospace, and pharmaceuticals. They are used to improve efficiency, reduce waste, ensure product quality, and increase profitability. As they are predominantly used on the shopfloor, a good internationalization is crucial, especially because many operators are not familiar with English. This includes both the texts of the out of the box user interface and the texts generated by users within the system (like customer specific worker instructions).
The goal of this project is to develop a reuseable translation module/service that enables the MES solution developed by Carl-Zeiss MES Solutions, to provide texts to users in their native language. Starting point will be to translate from German to English, keeping the reusability for other languages in mind. To achieve that, the ability of the currently existing generative AI solutions like ChatGPT need to be evaluated.

